The labor market statistics across our and their samples are, generally speaking, quite similar. We start by looking at differences in input data-sets. Then look at differences across the output data-sets, and find no major differences in the statistics themselves. What proves to be binding, however, is missing labor market information for some relevant labor markers in their data. This is further developed on in Chapter 5.
4.1.1 Input data-sets
Code
ours_input <-"our_replication_data.dta"%>%paste0(dir_transfers_replication, "data/", .) %>% haven::read_dta() %>%as.data.table() %>% .[, .(year, cod6, prin, priw, prit, popibge)] theirs_input <-"main_exact_data_checkpointpre1.dta"%>%paste0(dir_transfers_replication, "data/processing/", .) %>% haven::read_dta() %>%as.data.table() %>% .[, .(year, cod6, prin,prin_b10_1, priw, prit, popibge)] # theirs_input %>% names() %>% .[stri_detect_fixed(., "prin")] %>% return_in_vector_format()# these <- c('prin_b10', 'prin_a10', 'prin', 'prin_1', 'prin_2', 'prin_3', 'prin_b10_1', 'prin_a10_1', 'prin_b10_2', 'prin_a10_2', 'prin_b10_3', 'prin_a10_3')# summary(theirs_input[, ..these]) # prin_b10 prin_a10 prin prin_1 prin_2 prin_3 prin_b10_1 prin_a10_1 # Min. : 0 Min. : -10 Min. :0.000e+00 Min. : 0.0 Min. : 0 Min. : 0 Min. : 0.0 Min. : 0.0 # 1st Qu.: 70 1st Qu.: 42 1st Qu.:1.240e+02 1st Qu.: 13.0 1st Qu.: 15 1st Qu.: 47 1st Qu.: 7.0 1st Qu.: 0.0 # Median : 235 Median : 273 Median :5.390e+02 Median : 74.0 Median : 119 Median : 214 Median : 36.0 Median : 13.0 # Mean : 1522 Mean : 5130 Mean :4.021e+05 Mean : 283.9 Mean : 1954 Mean : 4358 Mean : 101.5 Mean : 144.2 # 3rd Qu.: 762 3rd Qu.: 1527 3rd Qu.:2.307e+03 3rd Qu.: 268.0 3rd Qu.: 764 3rd Qu.: 948 3rd Qu.: 113.0 3rd Qu.: 90.0 # Max. :742497 Max. :3703141 Max. :1.000e+09 Max. :14186.0 Max. :855568 Max. :3624841 Max. :3135.0 Max. :12250.0 # NA's :34467 NA's :34483 NA's :34162 NA's :34188 NA's :34188 NA's :34188 NA's :12244 NA's :12244 # prin_b10_2 prin_a10_2 prin_b10_3 prin_a10_3 # Min. : 0.0 Min. : 0 Min. : 0.0 Min. : 0 # 1st Qu.: 4.0 1st Qu.: 0 1st Qu.: 28.0 1st Qu.: 0 # Median : 20.0 Median : 54 Median : 98.0 Median : 45 # Mean : 163.7 Mean : 1256 Mean : 919.1 Mean : 2384 # 3rd Qu.: 77.0 3rd Qu.: 424 3rd Qu.: 363.0 3rd Qu.: 304 # Max. :91411.0 Max. :685213 Max. :649329.0 Max. :2917088 # NA's :12244 NA's :12244 NA's :12244 NA's :12244 # checking for duplicates: none# ours_input %>% # .[, GRP := .GRP,.(year, cod6)] %>% # .[duplicated(GRP)]# # theirs_input %>% # .[, GRP := .GRP,.(year, cod6)] %>% # .[duplicated(GRP)]
4.1.1.1 Missing Private Employment over time
We perform the following analysis to determine whether the differences across our and their estimation samples stems from missing private employment data in the original input data-sets.
Their code drops observations (municipality-years) with missing private and public employment. Our code only drops observations with missing public employment. In Chapter 5, we see that their dropping of missing public employment pubn barely alters the composition of their output data-set; thus the binding constraint is the line of code which drops observations with missing private employment prin.
This line in the code is what drives differences across our and their samples. Here, we first look at the distribution of missing private employment prin over time and across municipality size to see if there are any patterns, comparing their data to ours. We then select a different private employment variable prin_b10_1 in their data and compare it to ours. We conclude that the missing observations introduced into their sample truly come from dropping missing prin.
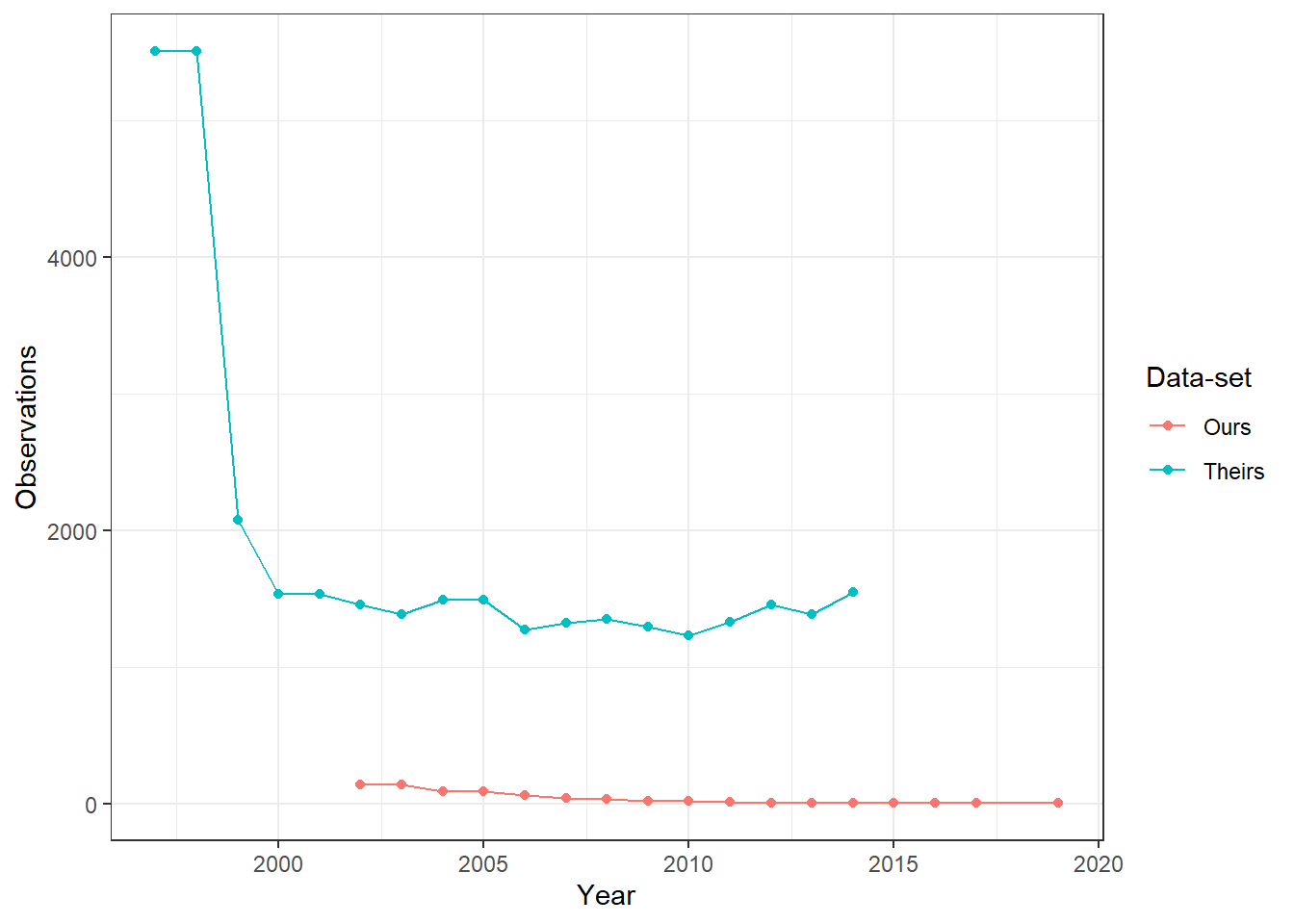
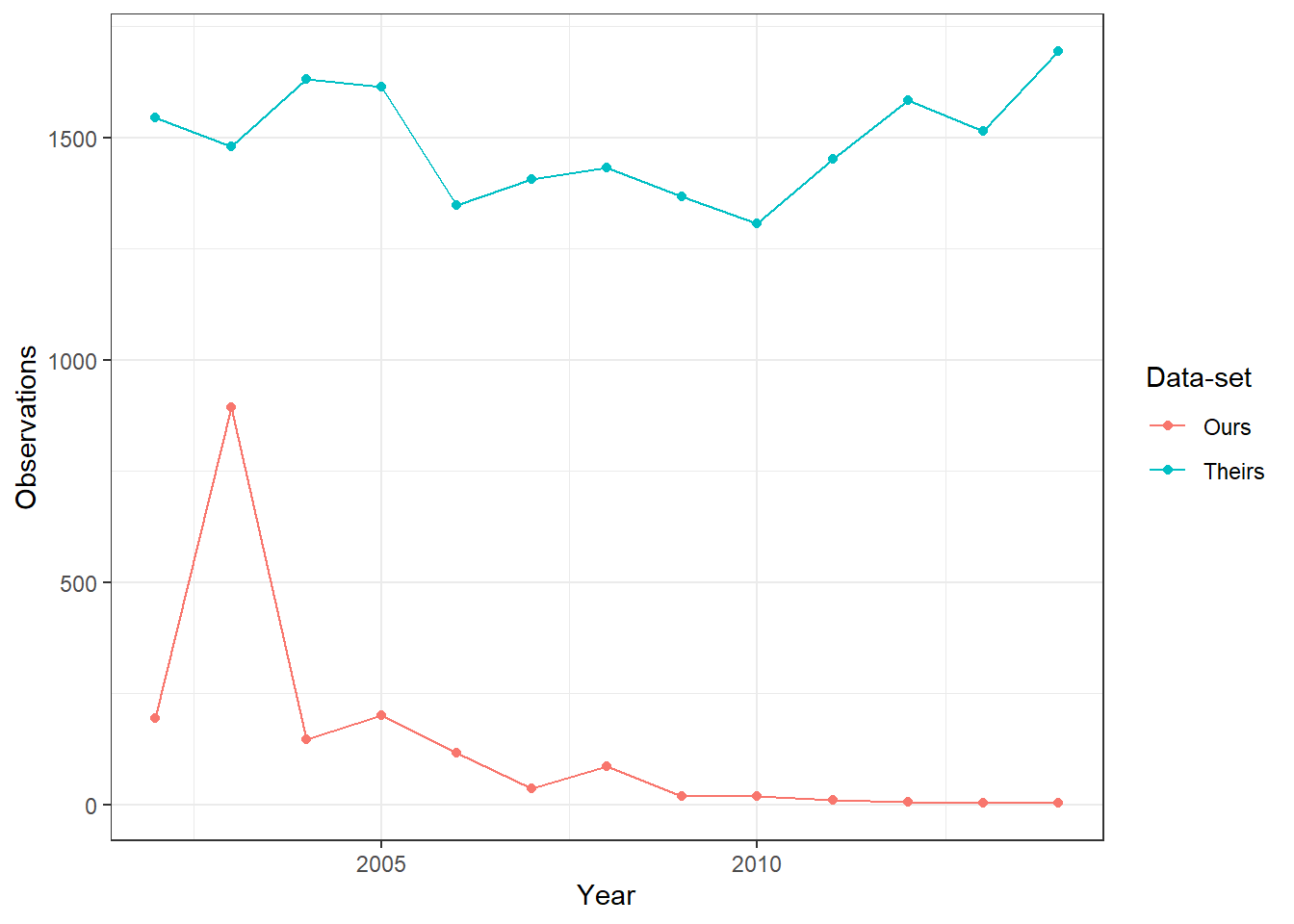
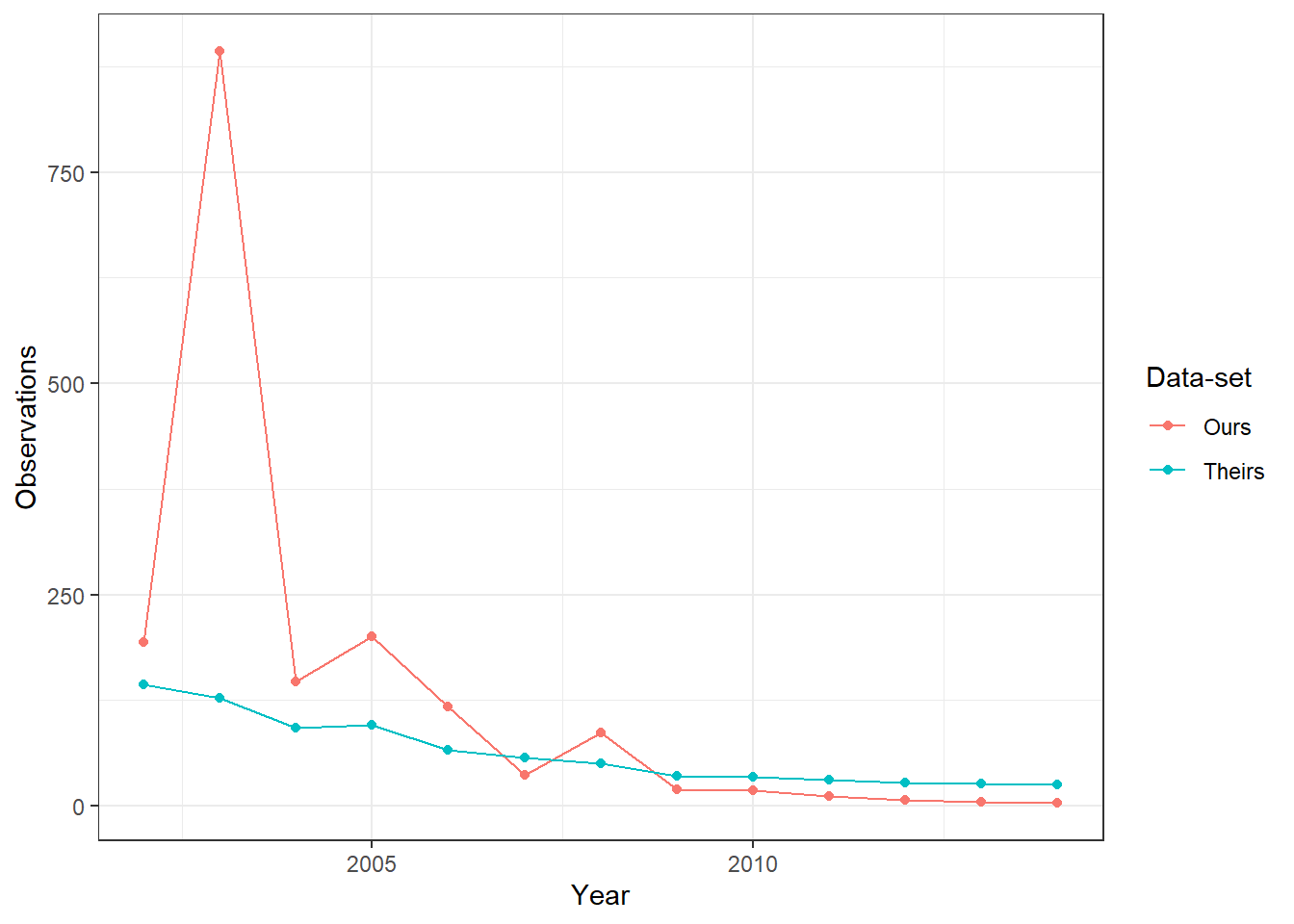
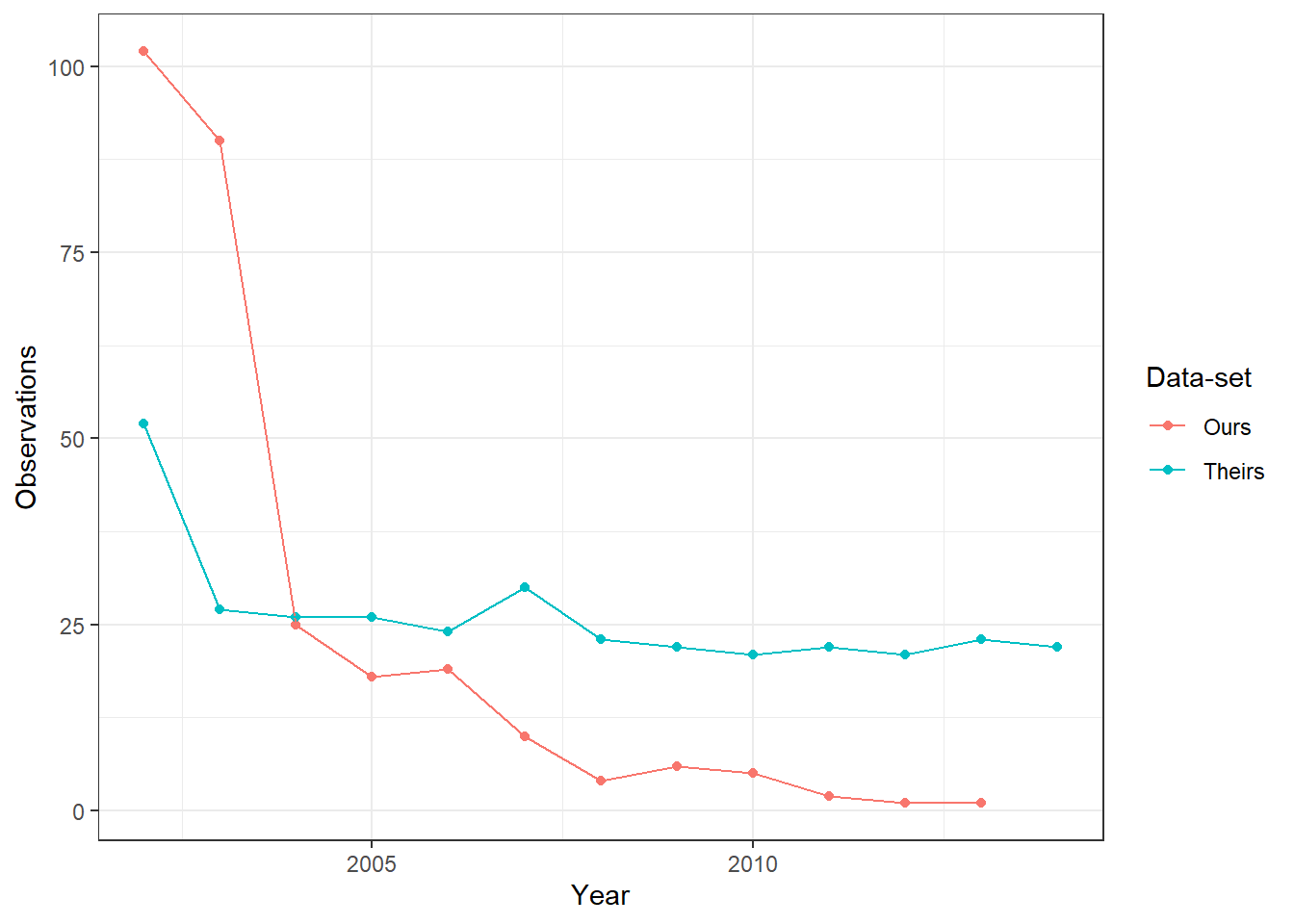
Figure 4.1 (tab Missing prin over time) shows the number of missing municipality-years in each input data-set. It illustrates that their data-set has a considerable number of municipality-years with missing private employment prin information. For a better comparison, we only keep municipality years common to both input data-sets and present it this in Figure 4.2 (tab Missing prin over time - same sample). Again, we see that their data-set has a lot of missing observations. Furthermore, we noticed that while some labor market variables associated with private employment like prin have many missing observations in their data, others like prin_b10_1, which measures private employment for agricultural firms below 10 workers, have a similar number of missing observations to our data ( see Figure 4.3). When comparing missing prin (in our data) vs missing prin_b10_1 (in their data), we also notice the roughly half of the missing observations in one data-set are also missing in the other. In Figure 4.4 (tab Missing prin_b10_1 over time - same sample - no common missings), we remove these common missing municipality-years and see that across both data-sets, our data has a similarly small average number of missing municipalities to theirs. This figure also highlights that while our missing data tapers off to zero over time, theirs is constant between 20-30 missing municipality years when using the alternate prin_b10_1 variable.
input_missing_by_year %>%ggplot(., aes(x=year, y = value, color = variable)) +geom_point() +geom_line() +xlab("Year") +ylab("Observations") +labs(color="Data-set") +theme_bw()
(a) This figure presents the number of observations in each input data-set that have missing private employment for the variable prin. Both data-sets are indexed at the year-municipality level.
Figure 4.1: Missing Private Employment (prin) per year per input data-set
Code
# identify common mun-yearscommon_mun_years <-merge(ours_input[, .(cod6, year)], theirs_input[, .(cod6, year)], by =c("cod6", "year"), all=F)ours_input_missing_by_year2 <- ours_input %>%merge(common_mun_years, ., by =c("cod6", "year"), all=F) %>% .[is.na(prin)] %>% .[, .N, year] %>%rename(., Ours=N)theirs_input_missing_by_year2 <- theirs_input %>%merge(common_mun_years, ., by =c("cod6", "year"), all=F) %>% .[is.na(prin)] %>% .[, .N, year] %>%rename(., Theirs=N)merge(ours_input_missing_by_year2, theirs_input_missing_by_year2, by ="year", all=T) %>%melt.data.table(id.vars=c("year")) %>%ggplot(aes(x=year, y = value, color = variable)) +geom_point() +geom_line() +xlab("Year") +ylab("Observations") +labs(color="Data-set") +theme_bw()
(a) This figure presents the number of observations in each input data-set that have missing private employment for the variable “prin”. Both data-sets are indexed at the year-municipality level. This figure restricts the municipality-years to those common to both input data-sets.
Figure 4.2: Missing Private Employment (prin) per year per input data-set - Same Sample
Code
# identify common mun-yearscommon_mun_years <-merge(ours_input[, .(cod6, year)], theirs_input[, .(cod6, year)], by =c("cod6", "year"), all=F)ours_input_missing_by_year3 <- ours_input %>%merge(common_mun_years, ., by =c("cod6", "year"), all=F) %>% .[is.na(prin)] %>% .[, .N, year] %>%rename(., Ours=N)theirs_input_missing_by_year3 <- theirs_input %>%merge(common_mun_years, ., by =c("cod6", "year"), all=F) %>% .[is.na(prin_b10_1)] %>% .[, .N, year] %>%rename(., Theirs=N)merge(ours_input_missing_by_year3, theirs_input_missing_by_year3, by ="year", all=T) %>%melt.data.table(id.vars=c("year")) %>%ggplot(aes(x=year, y = value, color = variable)) +geom_point() +geom_line() +xlab("Year") +ylab("Observations") +labs(color="Data-set") +theme_bw()
(a) This figure presents the number of observations in each input data-set that have missing private employment for the variable “prin”. Both data-sets are indexed at the year-municipality level. This figure restricts the municipality-years to those common to both input data-sets.
Figure 4.3: Missing Private Employment (prin) per year per input data-set - Same Sample
(a) This figure presents the number of observations in each input data-set that have missing private employment for the variable “prin”. Both data-sets are indexed at the year-municipality level. This figure restricts the municipality-years to those common to both input data-sets.
Figure 4.4: Missing Private Employment (prin) per year per input data-set - Same Sample
4.1.1.2 Missing Private Employment across population sizes
A question that now emerges is why there are so many missing observations in their data for the prin variable.
One hypothesis is that the authors did not compute labor market statistics for municipality-years beyond their proposed sample of municipalities with populations between 6,793 - 47,537. Though there are indeed many observations with missing prin that extend beyond the sample, the hypothesis does not fully explain the missing data. because there is an equal amount of municipality-years beyond the sample that have a non-missing prin. Moreover, when we only look at in-sample municipality-years, again, we see a considerable number of missing prin.
Figure 4.5 shows us that a considerable portion of the missing observations would be excluded from the sample because they go beyond the prescribed municipality sizes. It also shows us that there is still a large number of missing observations that fall within these boundaries. Figure 4.6 zooms in and shows us that there is still a considerable number of missing observations.
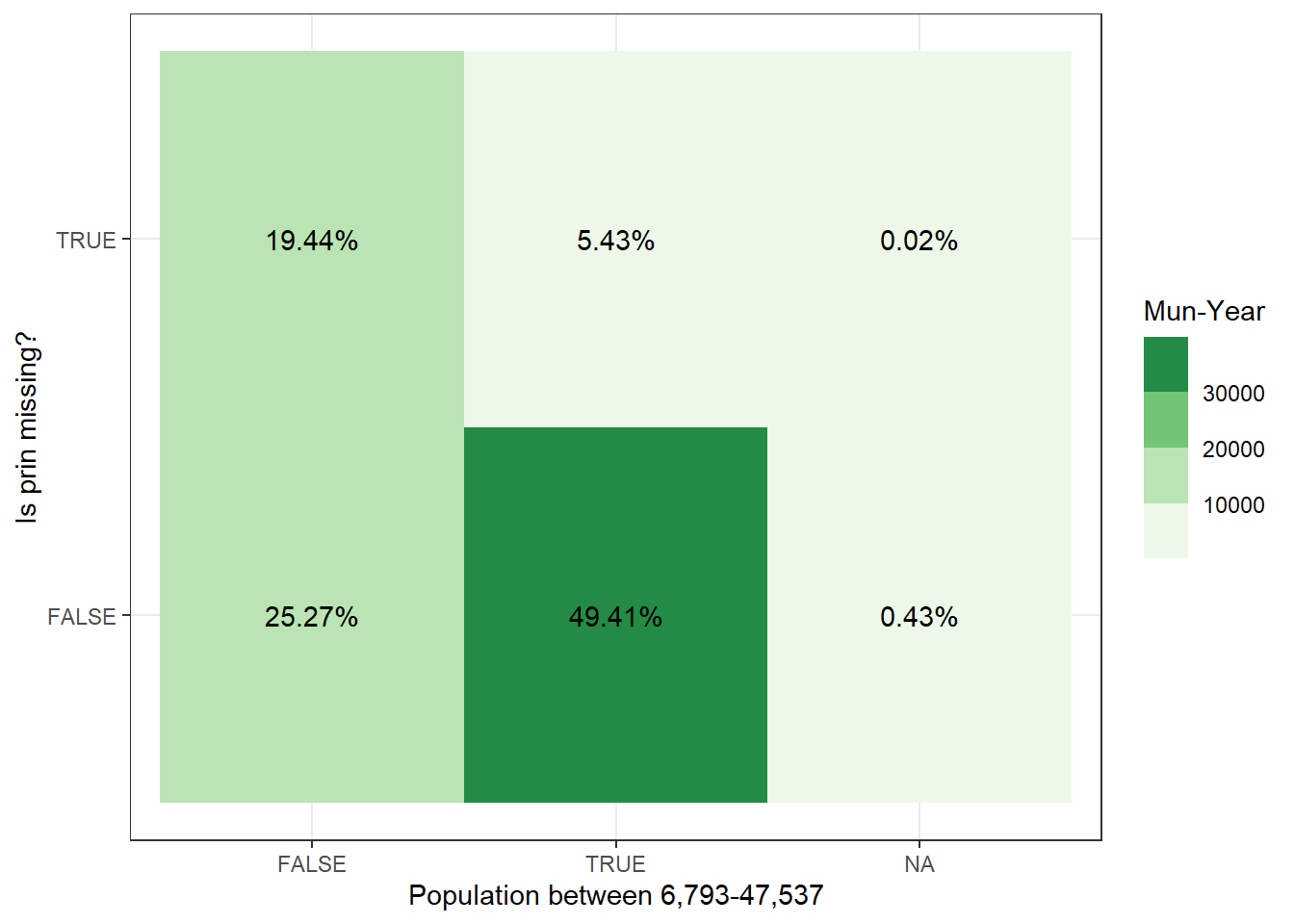
Figure 4.7 shows us that 55% percent of the observations in their data are municipalities that fall between the 6,793 and 47,537 population cut-offs. This is a promising lead, as it greatly reduces the complexity of the issue. The majority of the in-sample data is not missing.
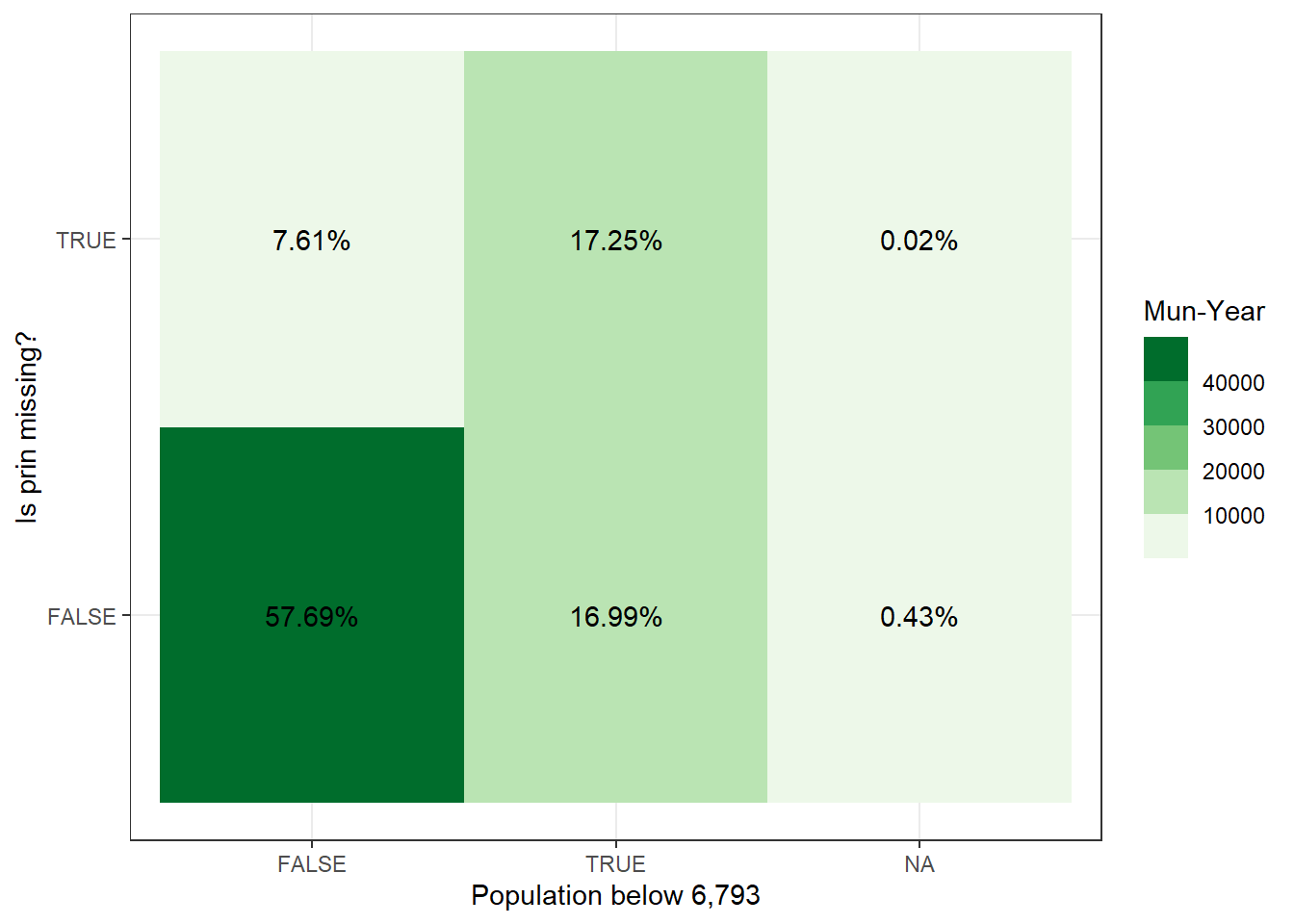
Figure 4.8 shows us that roughly half of the municipality-years that fall below the population cut-off are missing. This highlights the fact that the population cut-off is not the full reason for having a large number of missing observations.
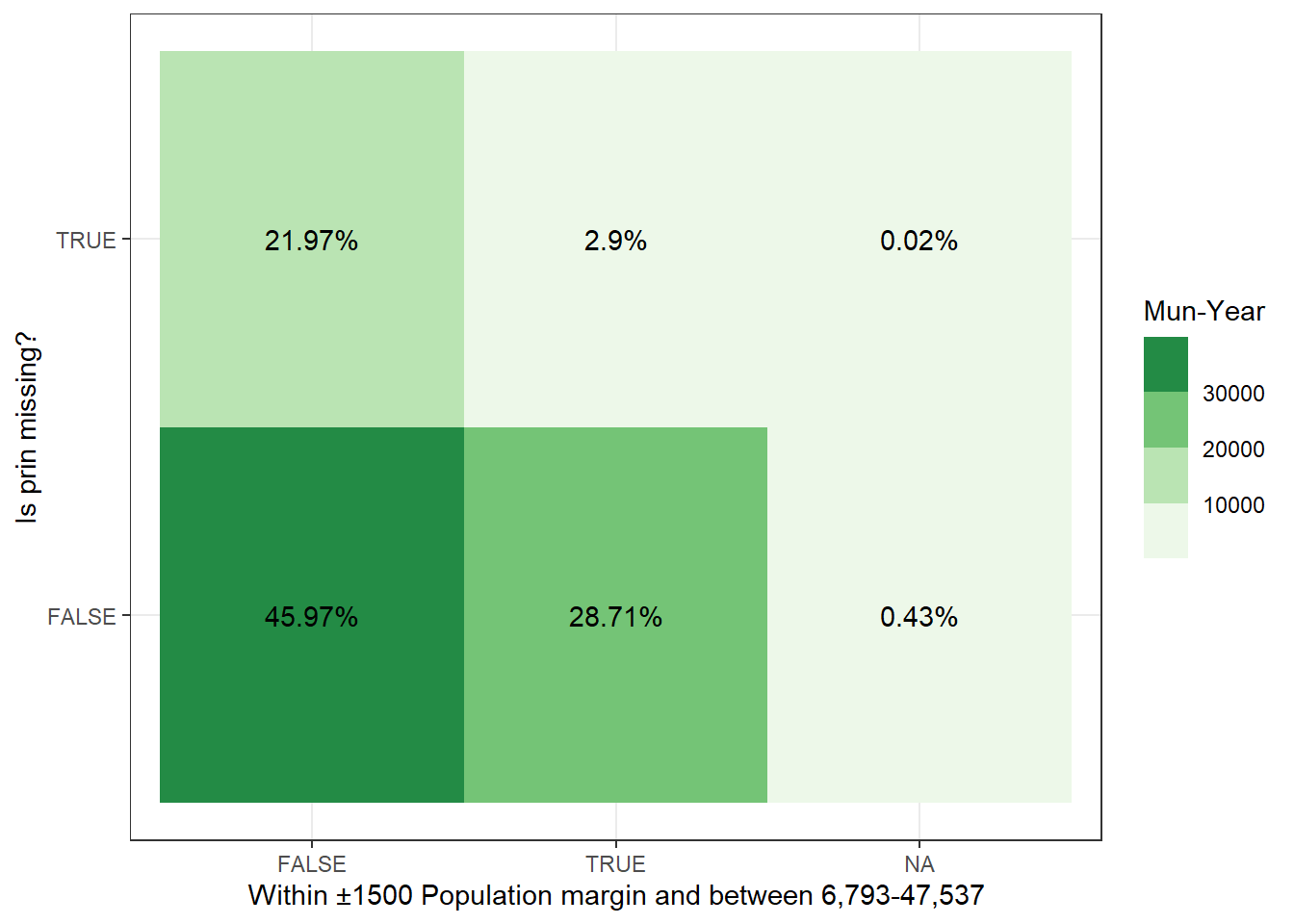
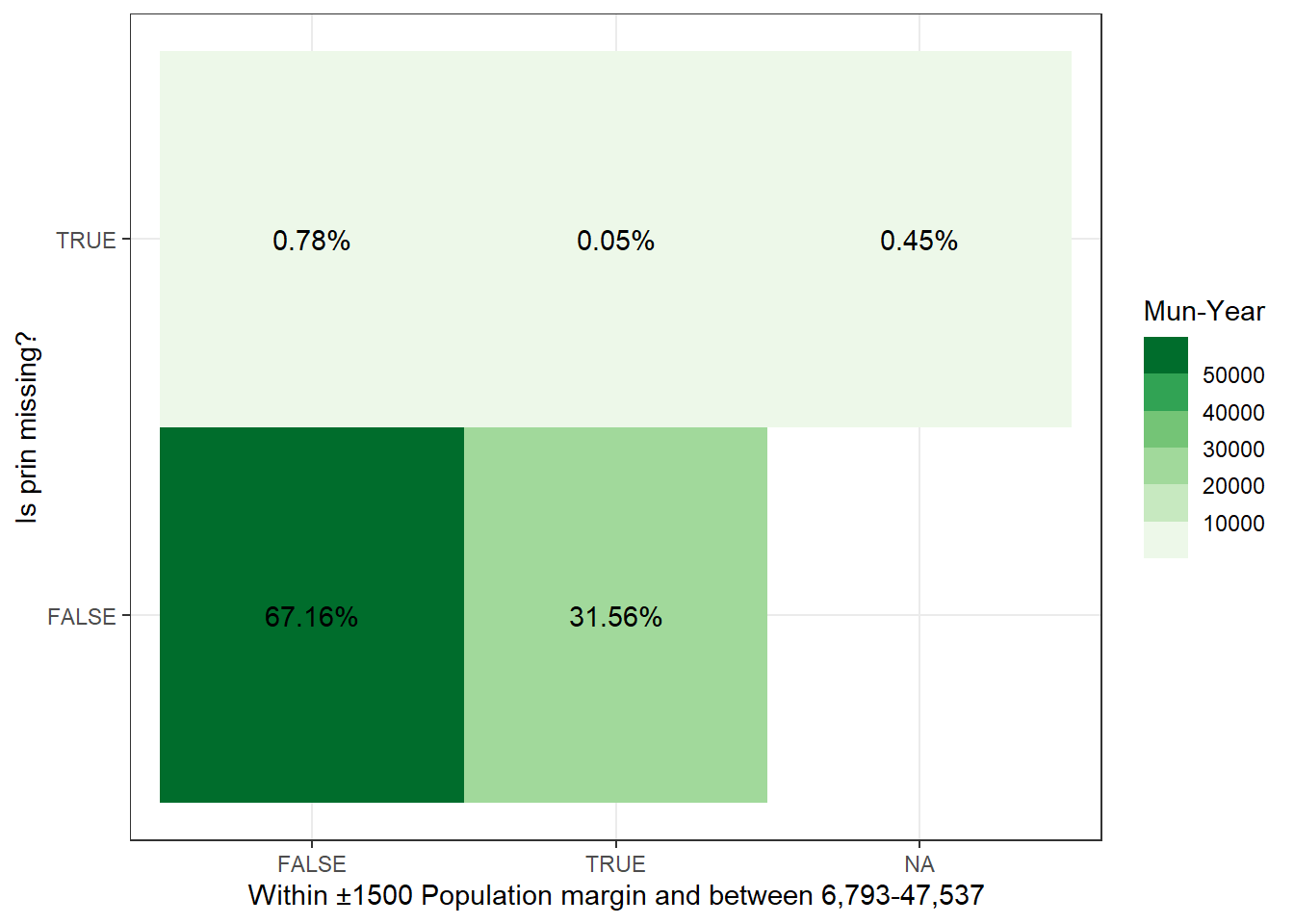
Figure 4.9 shows us that when we further sub-divide the data, only considering municipality-years with populations between the 6,793 and 47,537 population bounds and within ±1500 people from the FPM cut-offs, roughly 9% (\(\frac{2.79}{2.79+28.41}\)) of the sample has missing prin. Figure 4.10 presents the same breakdown but for our data. In contrast to their 9%, we have 0.1% \(\frac{0.05}{0.05 + 31.15}\) of missing observations.
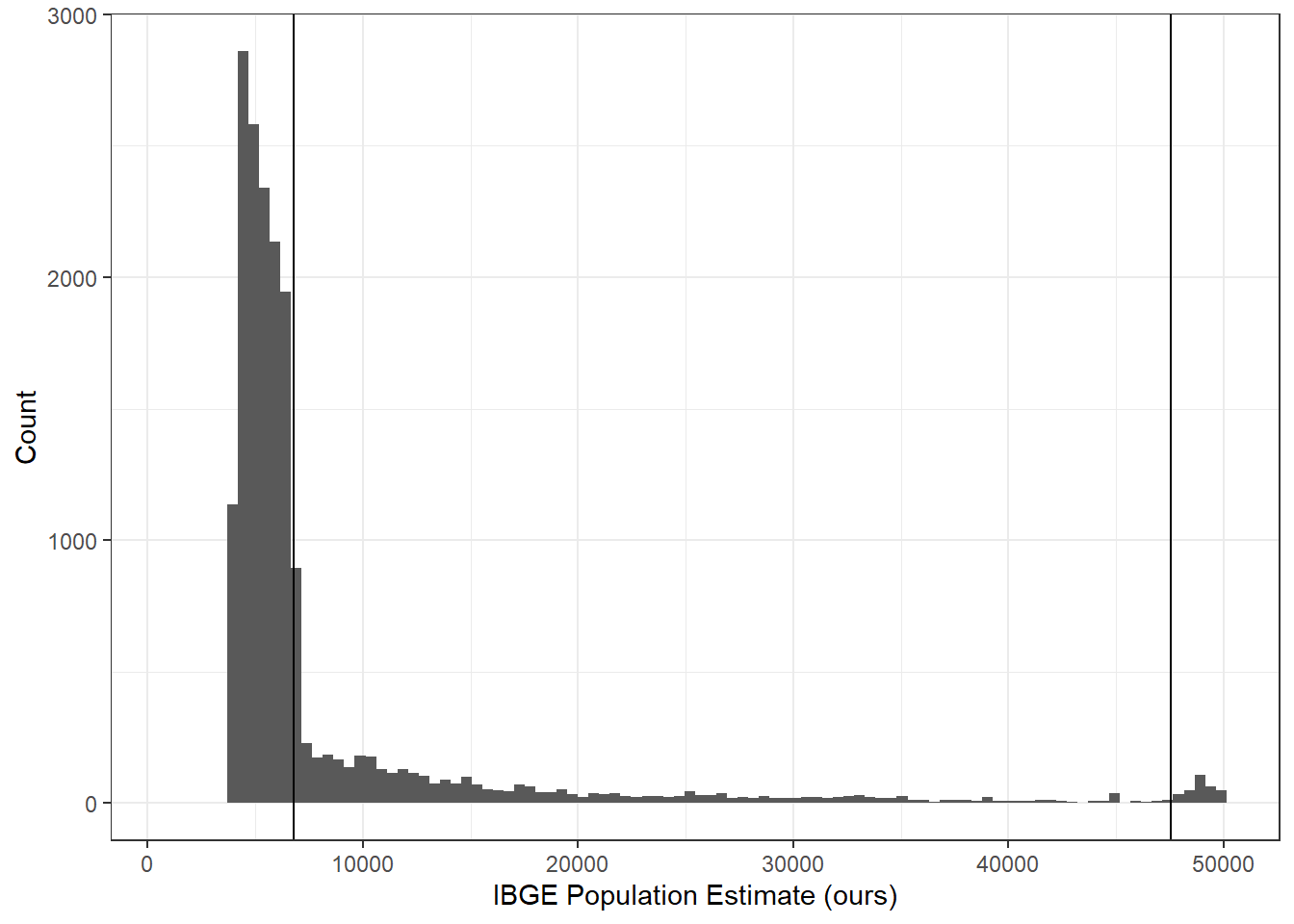
(a) This figure plots the population distribution of municipality-years with missing private employment data prin in our data. We take all of the municipality years with populations less than 50,000 (according to our population estimate) between 2002-2014 and plot the ditribution of their population estimates. The dark lines highlight the upper and lower sample cut-offs; any municipality beyond these would be excluded.
Figure 4.5: Population distribution for municipality-years with missing prin (in our their data)
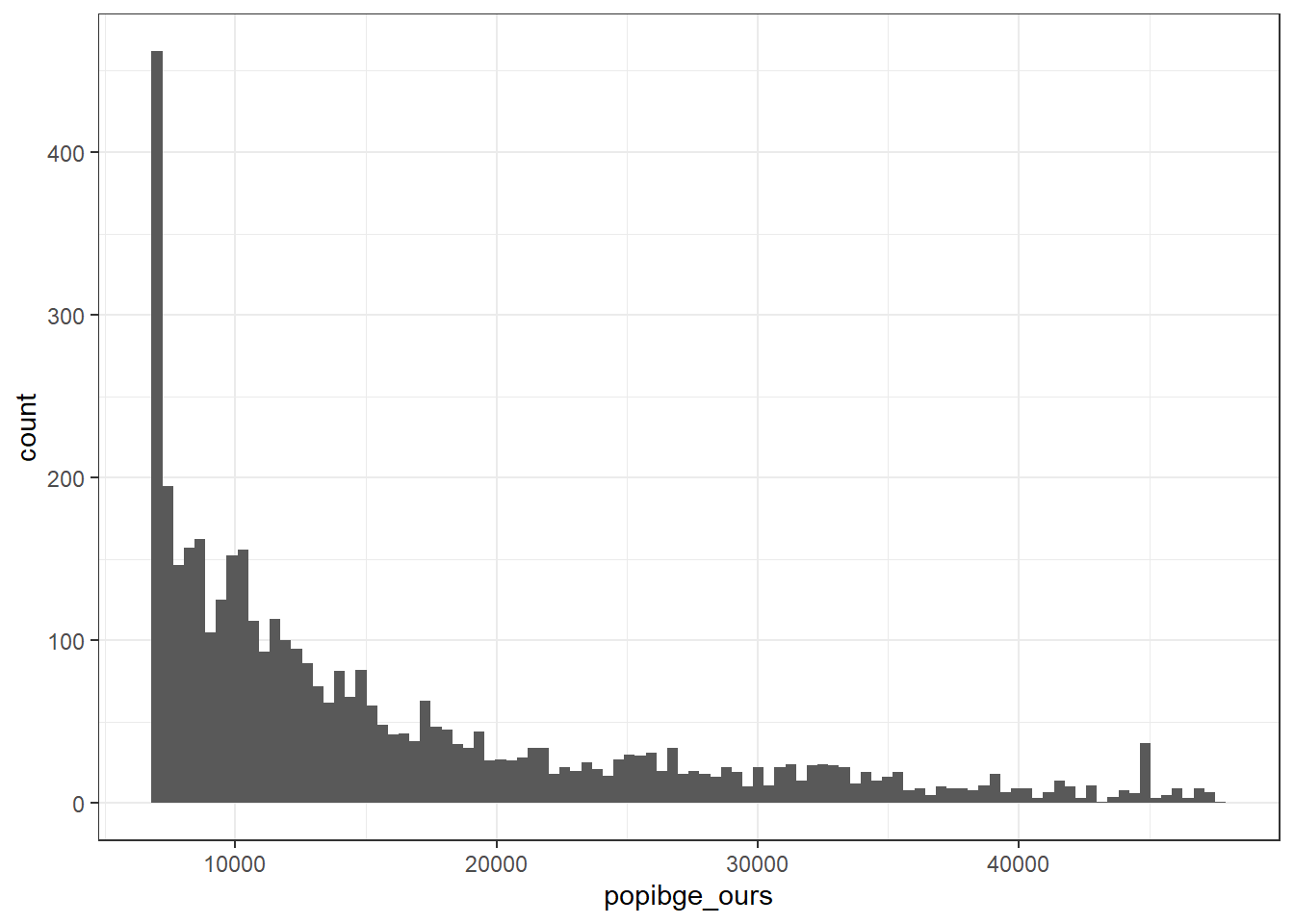
(a) This figure plots the population distribution of municipality-years with missing private employment data prin in our data. We take all of the municipality years with populations between 6,793 and 47,537 in the previous year (according to our population estimate) between 2002-2014 and plot the ditribution of their population estimates.
Figure 4.6: Population distribution for municipality-years with missing prin (in our our data)
# how may mun-years have a population between 6793 - 47537 and have missing data?missing_prin_in_sample <- joint_pop_with_samples %>% .[, .N, .(is.na(prin_theirs), in_sample_ours)] %>% .[, perc :=round(100*(N/sum(N)), digits =2)]missing_prin_in_sample %>%ggplot(aes(x=in_sample_ours, y =`is.na`, fill=N, label=paste0(perc, "%"))) +geom_tile() +geom_text() +scale_fill_fermenter(palette ="Greens", direction =1) +xlab("Population between 6,793-47,537") +ylab("Is prin missing?") +labs(fill="Mun-Year") +theme_bw()
(a) This visualization breaks down the data-set by whether prin is missing in their data and whether the population falls between the upper and lower cut-offs of 6,793 and 47,537.
Figure 4.7: Missing prin vs Between Upper and Lower populational bounds
Code
# how may mun-years have a population below 6793 and have missing data?joint_pop_with_samples %>% .[, .N, .(is.na(prin_theirs), below_6793_ours)] %>% .[, perc :=round(100*(N/sum(N)), digits =2)] %>%# .[below_6793_ours==TRUE] %>% ggplot(aes(x=below_6793_ours, y =`is.na`, fill=N, label=paste0(perc, "%"))) +geom_tile() +geom_text() +scale_fill_fermenter(palette ="Greens", direction =1) +xlab("Population below 6,793") +ylab("Is prin missing?") +labs(fill="Mun-Year") +theme_bw()
(a) This visualization breaks down the data-set by whether prin is missing in their data and whether the population falls below the lower 6,793 cut-off.
Figure 4.8: Missing prin vs Below Lower populational bound
Code
# add the population cut-offs to the datafor(i in1:nrow(population_thresholds)){# message_with_lines(i) POP_CUTOFF <- population_thresholds[i, min_popest] POP_CUTOFF_max <- population_thresholds[i+1, min_popest] joint_pop_with_samples[popibge_ours>=POP_CUTOFF, population_cutoff_min := POP_CUTOFF] joint_pop_with_samples[popibge_ours>=POP_CUTOFF, population_cutoff_max := POP_CUTOFF_max]}# determine whether the observation falls within the 1500 margin joint_pop_with_samples %<>% .[, within_margin_lower := (abs(popibge_ours-population_cutoff_min)<=1500)] %>% .[, within_margin_upper := (abs(population_cutoff_max-popibge_ours)<=1500)] %>% .[, within_margin := within_margin_upper==TRUE| within_margin_lower==TRUE ] %>% .[, within_margin := within_margin ==TRUE& in_sample_ours==TRUE ]
Code
# how may mun-years have a population between 6793 - 47537 and have missing data?missing_prin_within_margin <- joint_pop_with_samples %>% .[, .N, .(is.na(prin_theirs), within_margin)] %>% .[, perc :=round(100*(N/sum(N)), digits =2)]missing_prin_within_margin %>%ggplot(aes(x=within_margin, y =`is.na`, fill=N, label=paste0(perc, "%"))) +geom_tile() +geom_text() +scale_fill_fermenter(palette ="Greens", direction =1) +xlab("Within ±1500 Population margin and between 6,793-47,537") +ylab("Is prin missing?") +labs(fill="Mun-Year") +theme_bw()
(a) This visualization breaks down the data-set by whether prin is missing in their data and whether the municipality-year population falls between the upper and lower cut-offs of 6,793 and 47,537 and within the ±1500 margin from population cut-offs.
Figure 4.9: Missing prin vs Between 1500 Cut-off Margins
Code
# how may mun-years have a population between 6793 - 47537 and have missing data?missing_prin_within_margin <- joint_pop_with_samples %>% .[, .N, .(is.na(prin_ours), within_margin)] %>% .[, perc :=round(100*(N/sum(N)), digits =2)]missing_prin_within_margin %>%ggplot(aes(x=within_margin, y =`is.na`, fill=N, label=paste0(perc, "%"))) +geom_tile() +geom_text() +scale_fill_fermenter(palette ="Greens", direction =1) +xlab("Within ±1500 Population margin and between 6,793-47,537") +ylab("Is prin missing?") +labs(fill="Mun-Year") +theme_bw()
(a) This visualization breaks down the data-set by whether prin is missing in their data and whether the municipality-year population falls between the upper and lower cut-offs of 6,793 and 47,537 and within the ±1500 margin from population cut-offs.
Figure 4.10: Missing prin vs Between 1500 Cut-off Margins
4.1.2 Final data-set
Here we restrict both data-sets to the municipality-years common to both. We do so to have direct comparisons of ours and their labor market statistics and FPM transfers.
Code
ours <-"main_exact_data_our_corrected_LM.dta"%>%paste0(dir_transfers_replication, "data/processing/", .) %>% haven::read_dta() %>%as.data.table() theirs <-"main_exact_data_our_deflator.dta"%>%paste0(dir_transfers_replication, "data/processing/", .) %>% haven::read_dta() %>%as.data.table()# get mun,-yearsours_munyear <- ours[, .N, .(codigo, year)][, N:=NULL][, Ours :=1]theirs_munyear <- theirs[, .N, .(codigo, year)][, N:=NULL][, Theirs :=1]# merge both in order to understand what the issue isboth_all <-merge(ours_munyear, theirs_munyear, by=c("codigo", "year"), all=T)# restrict them to the correct rows though ours_restricted <- both_all %>%copy() %>% .[Ours==1&Theirs==1] %>%merge(x=ours, y=., by=c("codigo", "year"), all=F ) %>%# restrict by years as well .[year>=2002& year <=2014]theirs_restricted <- both_all %>%copy() %>% .[Ours==1&Theirs==1] %>%merge(x=theirs, y=., by=c("codigo", "year"), all=F ) %>%# restrict by years as well .[year>=2002& year <=2014]# save data-sets -----------------"main_exact_data_our_corrected_LM_common_sample.dta"%>%paste0(dir_transfers_replication, "data/processing/", .) %>% haven::write_dta(ours_restricted, .)"main_exact_data_our_deflator_common_sample.dta"%>%paste0(dir_transfers_replication, "data/processing/", .) %>% haven::write_dta(theirs_restricted, .)# -----------------ours_restricted_sumstats <-data.table("Rows"=nrow(ours_restricted),"Total IBGE Population"=sum(ours_restricted$popibge, na.rm=T),"Avg. Avg. Wage"=mean(ours_restricted$priw, na.rm=T),"Avg. Log Avg. Wage"=mean(ours_restricted$lpriw, na.rm=T),"Avg. Total Earnings"=mean(ours_restricted$prit, na.rm=T),"Avg. Log Total Earnings"=mean(ours_restricted$lprit, na.rm=T),"Sum Total Private Workers"=sum(ours_restricted$prin, na.rm=T),"Avg. Log Total Private Workers"=mean(ours_restricted$lprin, na.rm=T)) %>%t() %>%as.data.table(., keep.rownames=T) %>% .[, V1 :=round(V1, digits =3)] %>%rename_columns(current_names =c("rn", "V1"), new_names =c("Statistics", "Ours"))theirs_restricted_sumstats <-data.table("Rows"=nrow(theirs_restricted),"Total IBGE Population"=sum(theirs_restricted$popibge, na.rm=T),"Avg. Avg. Wage"=mean(theirs_restricted$priw, na.rm=T),"Avg. Log Avg. Wage"=mean(theirs_restricted$lpriw, na.rm=T),"Avg. Total Earnings"=mean(theirs_restricted$prit, na.rm=T),"Avg. Log Total Earnings"=mean(theirs_restricted$lprit, na.rm=T),"Sum Total Private Workers"=sum(theirs_restricted$prin, na.rm=T),"Avg. Log Total Private Workers"=mean(theirs_restricted$lprin, na.rm=T)) %>%t() %>%as.data.table(., keep.rownames=T) %>% .[, V1 :=round(V1, digits =3)] %>%rename_columns(current_names =c("rn", "V1"), new_names =c("Statistics", "Theirs")) comparisons <-merge(ours_restricted_sumstats,theirs_restricted_sumstats, by ="Statistics", all=T) %>% .[, `Equal?`:= Ours == Theirs] %>% .[order(`Equal?`)] %>% .[, `Ours over Theirs`:=round(Ours/Theirs, digits =2)] %>% .[order(`Ours over Theirs`)] options(scipen =15)comparisons[order(-`Equal?`)]
Comparing the Most restricted versions of our and their data
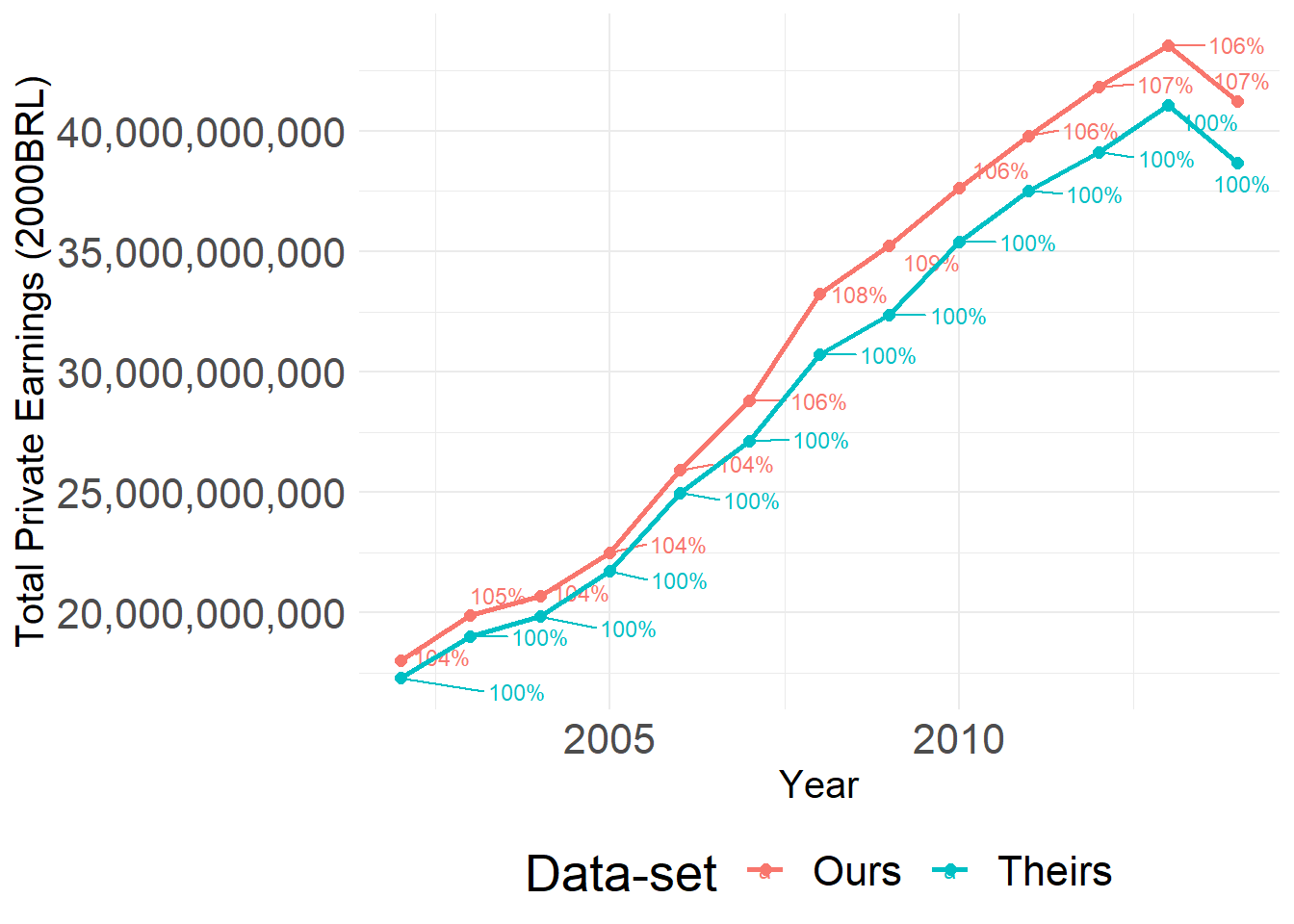
We plot the time series of total municipal private sector earnings for Our and Their data. These are not directly comparable as they use different deflators, but the sheer difference is alarming. We use the exact same municipality-years across both samples. The y-axis represents the total amount of wages in each sample for each year. The percentage is included for the reader to understand the difference in magnitude between one sample and the other; it is constructed as the ratio of our yearly total over their yearly total.
Total yearly Private Earnings for each data-set (not log)
We plot the time series of total municipal private sector earnings for Our and Their data. These are not directly comparable as they use different deflators, but the sheer difference is alarming. We use the exact same municipality-years across both samples. The y-axis represents the total amount of wages in each sample for each year. The percentage is included for the reader to understand the difference in magnitude between one sample and the other; it is constructed as the ratio of our yearly total over their yearly total.
Total yearly Private Earnings for each data-set (not log)
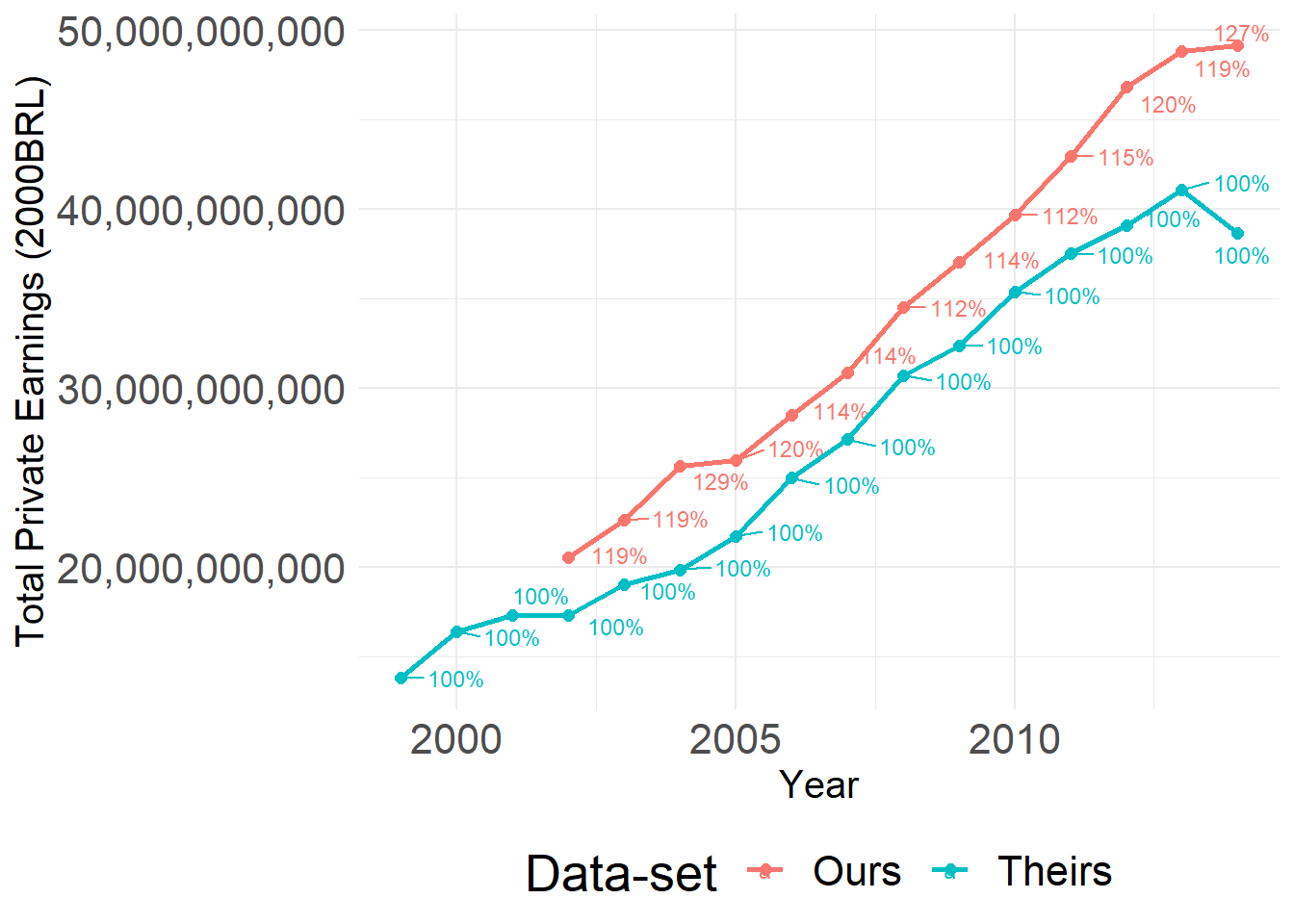
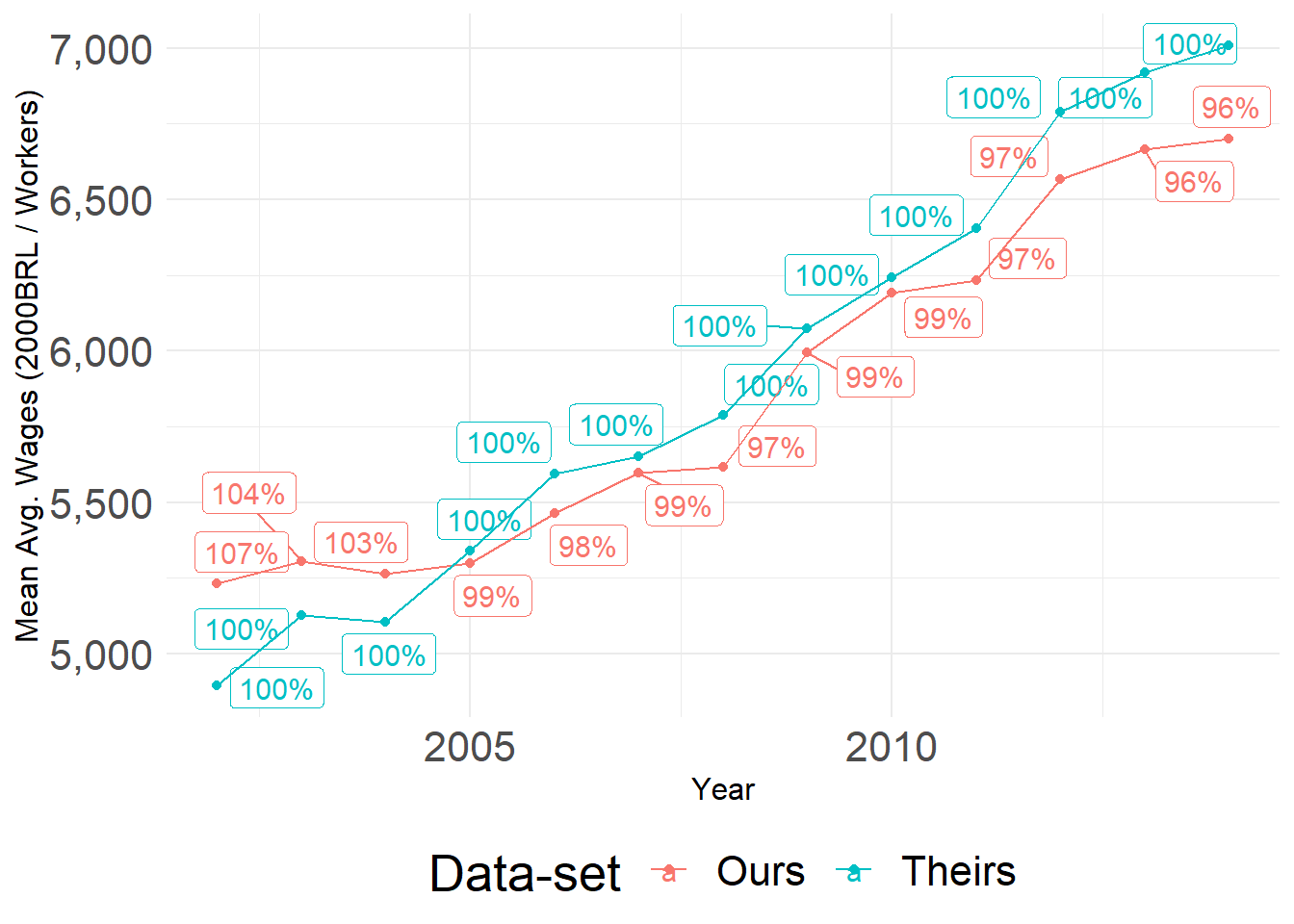
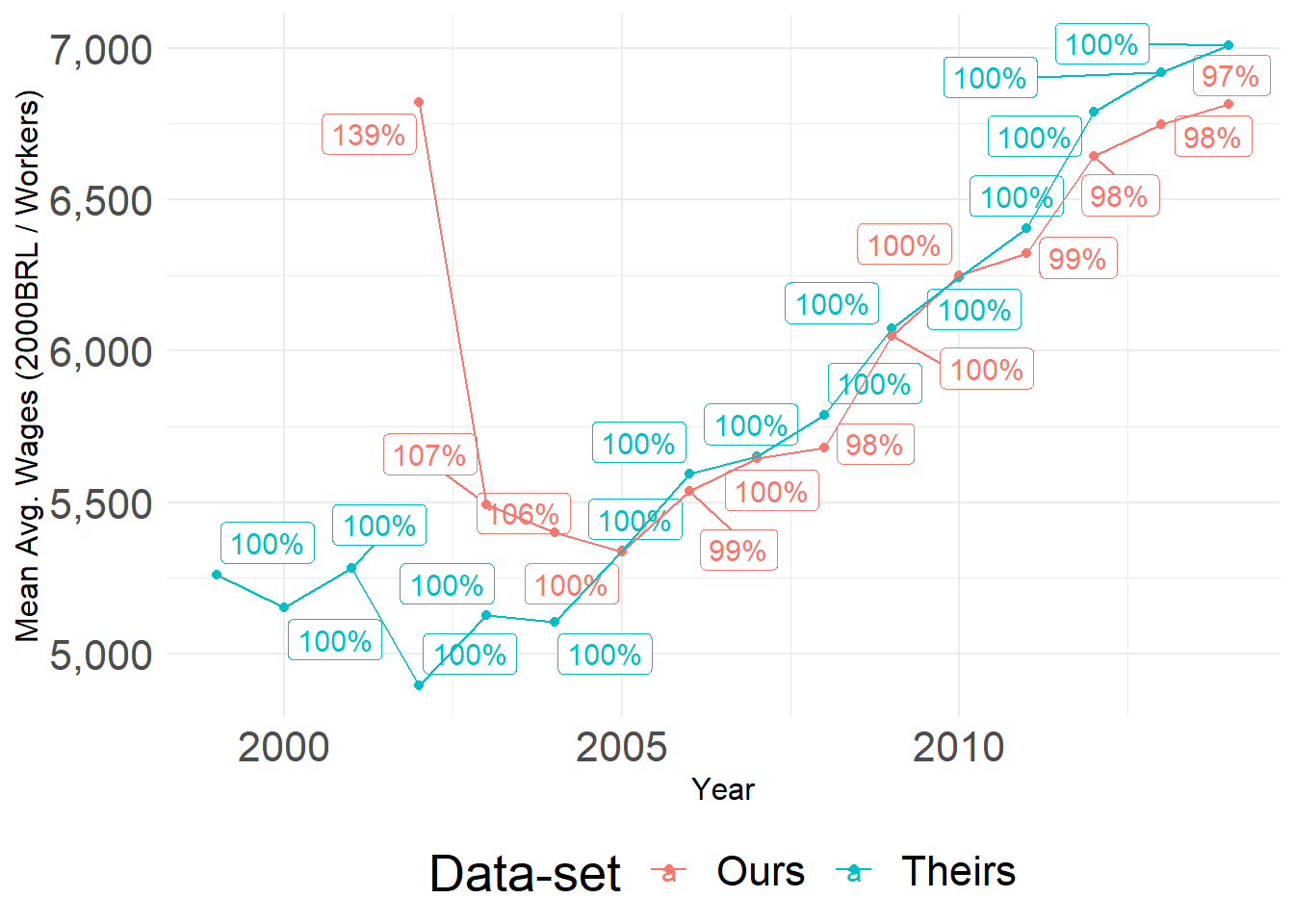
We plot the time series of average municipal private sector earnings for Our and Their data. The y axis is constructed by taking the average of each municipality-year mean wage. These are not directly comparable as they use different deflators, but the sheer difference is alarming. We use the exact same municipality-years across both samples. The y-axis represents the total amount of wages in each sample for each year. The percentage is included for the reader to understand the difference in magnitude between one sample and the other; it is constructed as the ratio of our yearly average over their yearly average.
Average Yearly Mean Private Earnings for each data-set (not log)
We plot the time series of average municipal private sector earnings for Our and Their data. The y axis is constructed by taking the average of each municipality-year mean wage. These are not directly comparable as they use different deflators, but the sheer difference is alarming. We use the exact same municipality-years across both samples. The y-axis represents the total amount of wages in each sample for each year. The percentage is included for the reader to understand the difference in magnitude between one sample and the other; it is constructed as the ratio of our yearly average over their yearly average.
Average Yearly Mean Private Earnings for each data-set (not log)
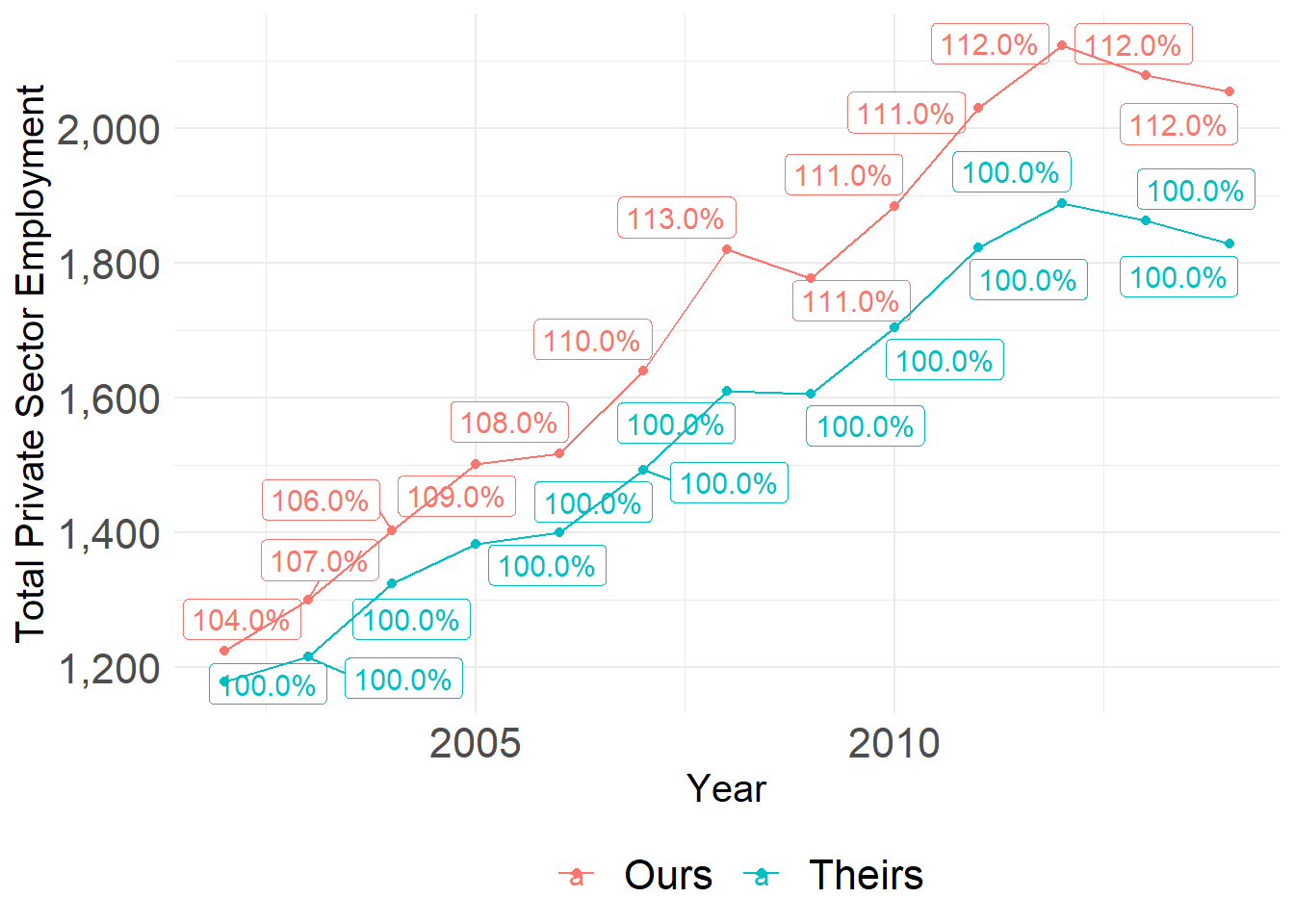
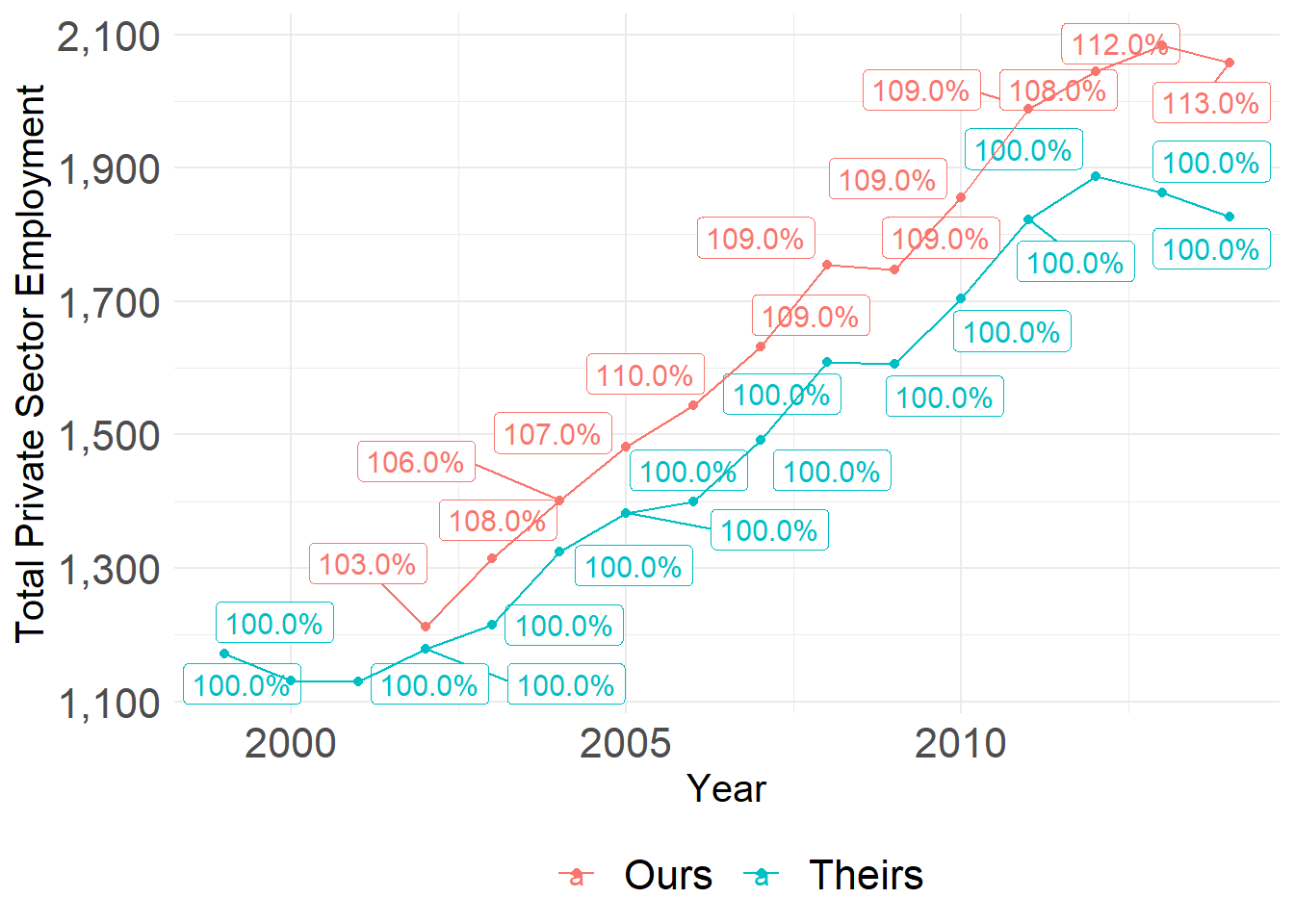
We plot the time series of total municipal private sector employment for Our and Their data. The y axis is constructed by summing the number ofo private sector workers in each municipality-year. These are directly comparable. We use the exact same municipality-years across both samples. The y-axis represents the total amount of wages in each sample for each year. The labels present the ratio (in percent) of our private sector municipality-year workforce estimate over theirs.
We plot the time series of total municipal private sector employment for Our and Their data. The y axis is constructed by summing the number ofo private sector workers in each municipality-year. These are directly comparable. We use the exact same municipality-years across both samples. The y-axis represents the total amount of wages in each sample for each year. The labels present the ratio (in percent) of our private sector municipality-year workforce estimate over theirs.