This document was created on Monday May 22nd to address the main bottle neck of the project: what drives the differences in composition (municipality-years) across our and their samples? The answer lies in missing labor market statistics in their data-set. More specifically, though there are municipality-years with all levels of private employment which are missing in their data, the two-thirds have less than 300 private workers (according to our data). While our data also has some missing municipalities (7 missing municipalities in ours that are not missing in theirs), they have 1122 missing municipalities (that are not missing in ours).
The next step is to review Chapter 4 and include a section where we look deeper into missing data for their raw data input data-sets.
5.1 How is the analysis structured? What is important to consider?
Project Structure
The analysis is structed in three phases: pre-cleaning, cleaning and output creation. First, we have the pre-cleaning files. These are not available in their documentation and are responsible for cleaning the input data-sets. Second, we have the cleaning file, which does all of the relevant cleaning. Since there are no additional modifications done to the data outside of a preserve-restore code chunk, we can save the data from the cleaning section and apply it to the output creation files. Lastly, we have the output creation files, which take in the clean data and create the visualizations available in the paper.
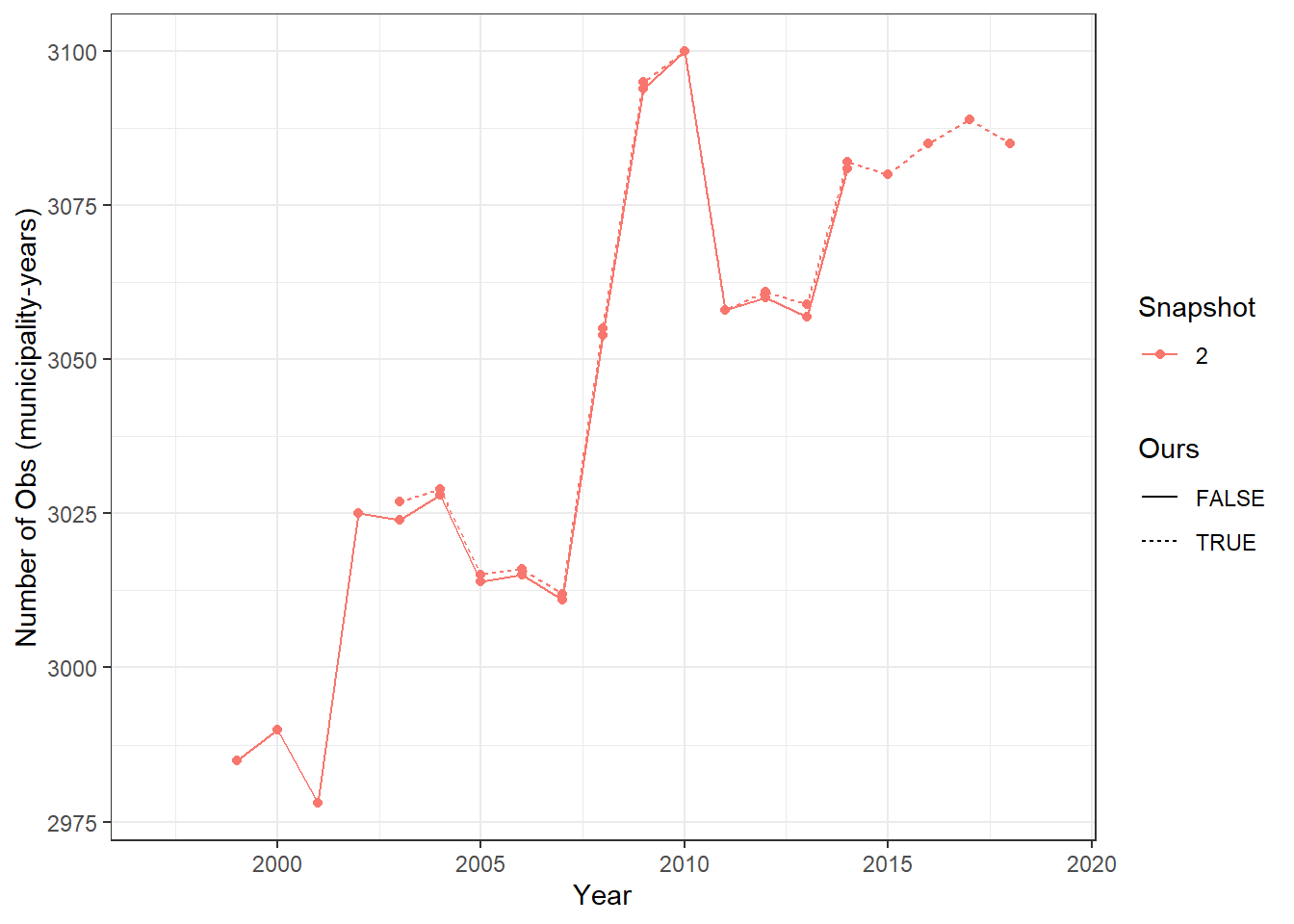
We focus on the cleaning codes. Specifically, we compare and contrast the state of the data-set at different points in their and our cleaning codes. In order to avoid any unnecessary differences across cleaning methodologies, we adapt their cleaning code for our data. At the same point in each code, we create 4 “snapshots” of number of yearly observations in each data-set. Snapshot 1 is taken once all of the relevant data is loaded in. Snapshot 2 is taken once observations for irrelevant (and boundary) years and observations with missing population & lagged population estimates are removed. Snapshot 3 is taken once we remove municipalities with missing private or public sector employment. Snapshot 4 is taken right before saving the data-set. Since we do not consider public employment in our data-set (for the purposes of the current output), we only drop observations with missing private sector employment. To get an equivalent comparison with their data, we create a version of their code (and data) with this looser constraint and see very little difference in outcomes.
5.2 How many observations do our and their data-sets have?
For starters, we start with the output data-sets to get a sense of what the major differences in observations are. Below we create two plots.
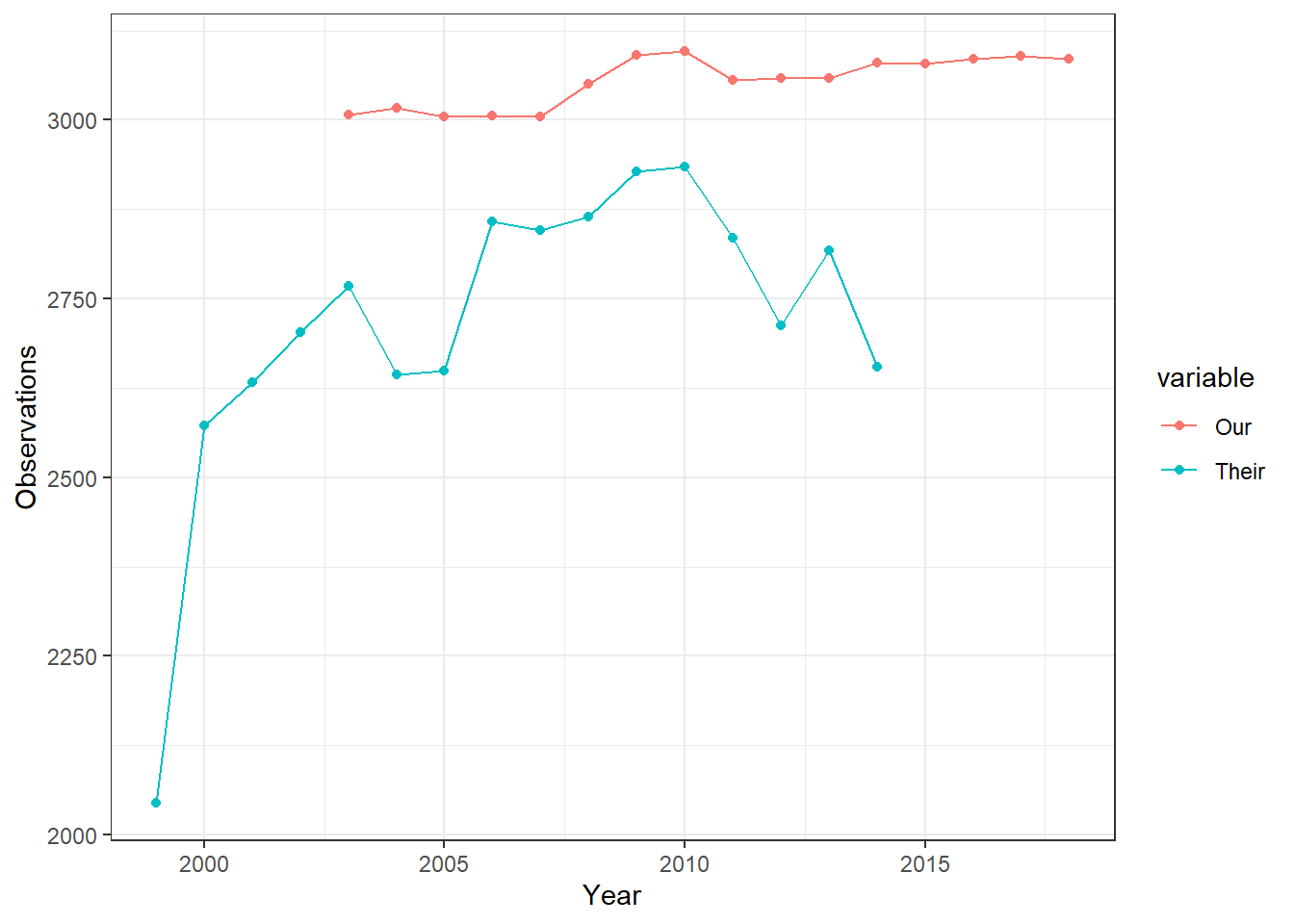
First, we compare the number of observations in our output data-set with theirs, for all of the relevant years. While the number of observations in our data varies little over time, the same cannot be said about their data-set.
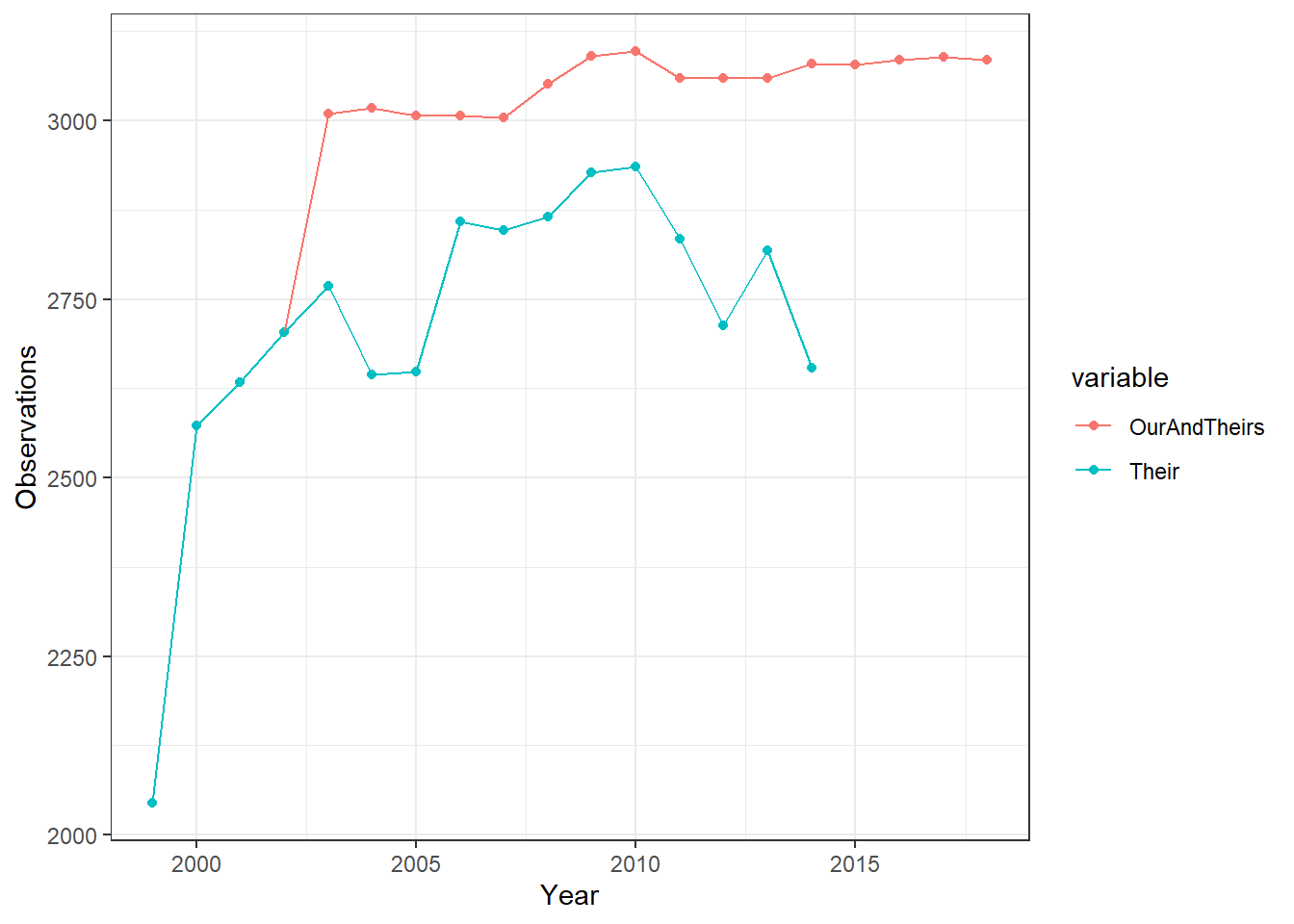
Second, we compare the number of observations in their data-set with a merged version of both data-sets. The objective here is to see whether there are many mutually exclusive municipality-years across the samples. Since the OurAndTheirs series is very similar in shape to Our series, their data-set must be lacking observations (rather than ours being larger but equally lacking).
5.3 Running Our and Their data cleaning files, line by line
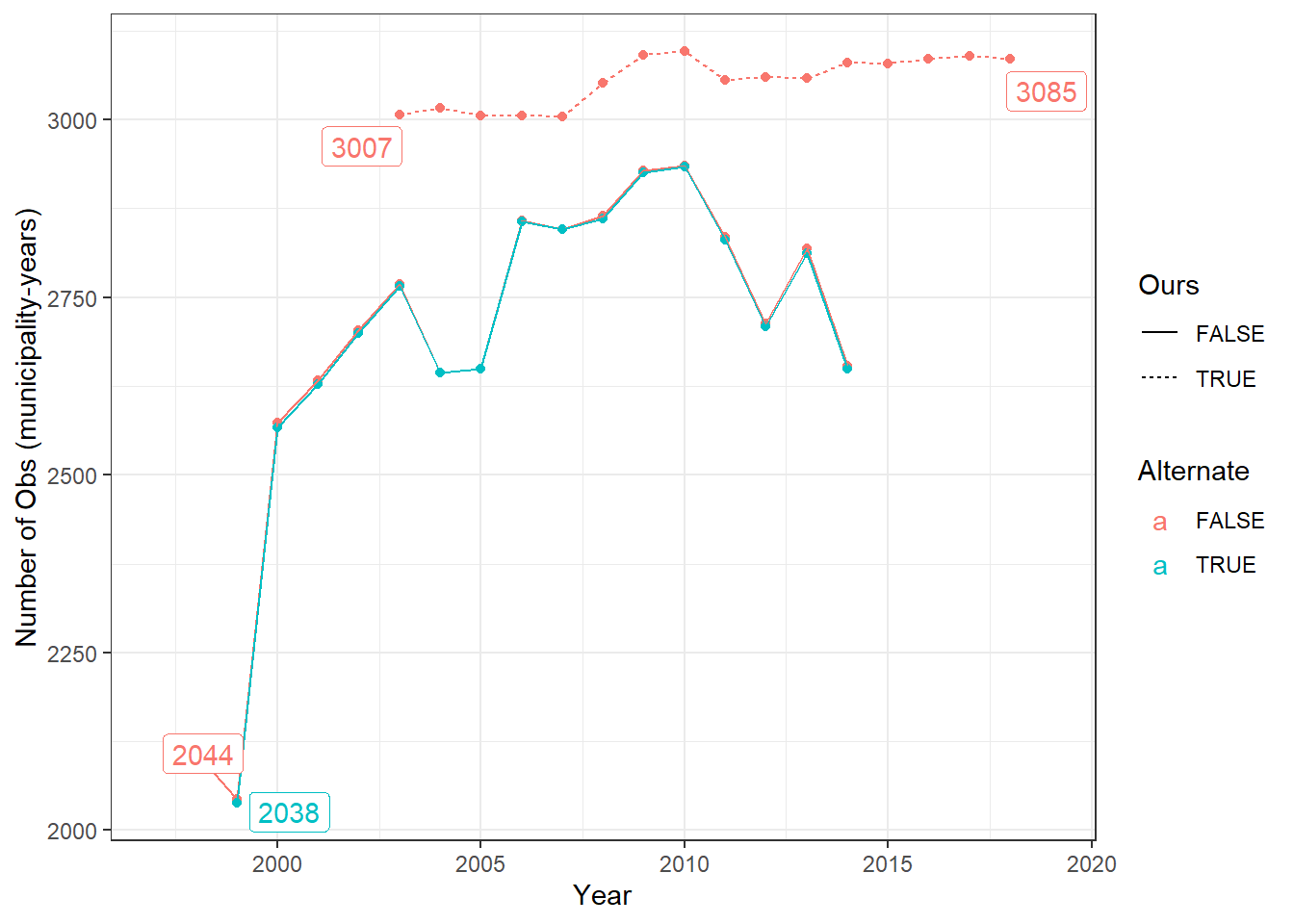
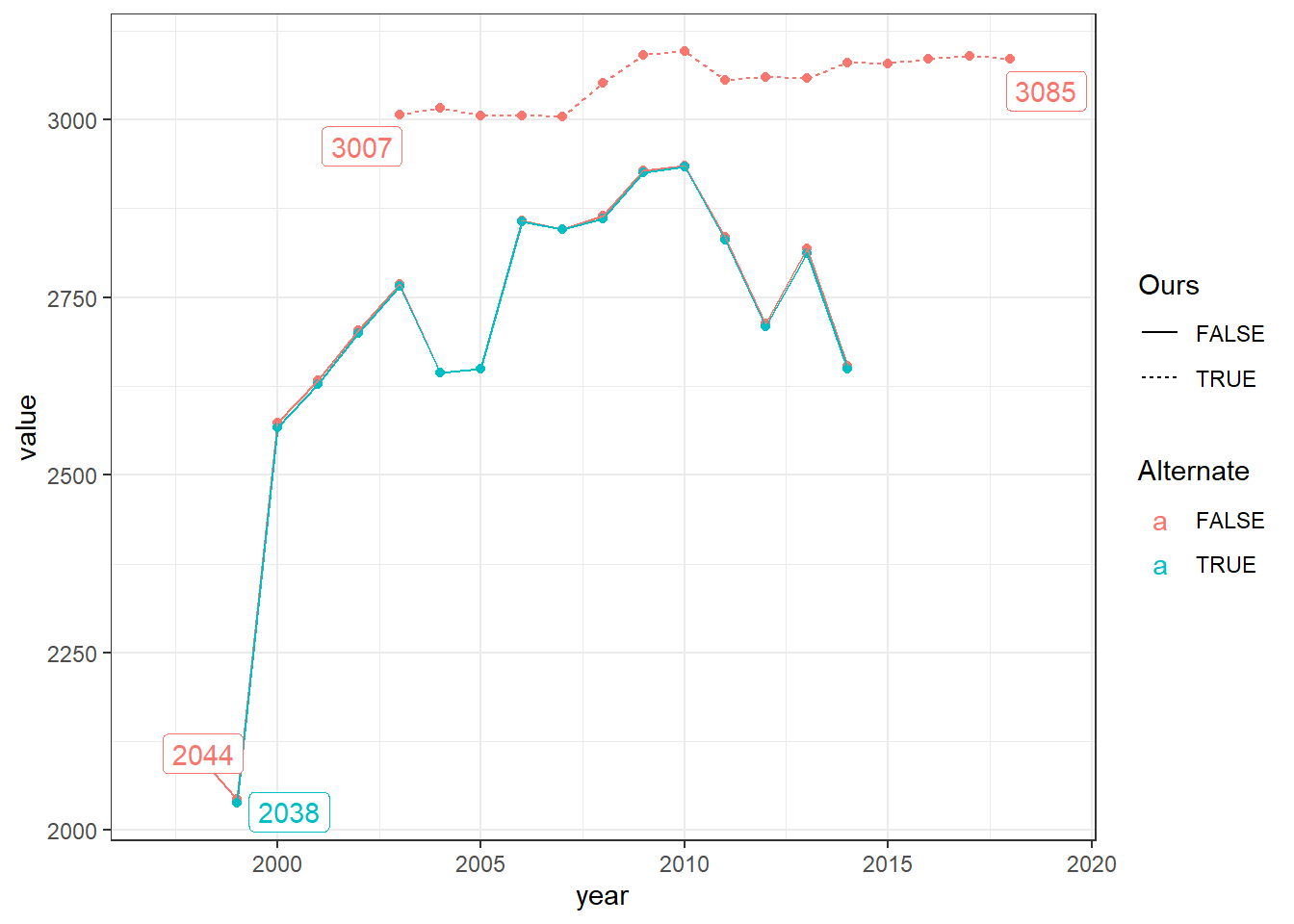
As was mentioned above, we create four snapshots of the data as it transits through the cleaning files. Since the original cleaning file drops missing public (pubn) and private (privn) municipality-year employment, but the figures only require the latter; we create two additional snapshots (alternate 3 and alternate 4) for their cleaning file, where we only drop missing private employment.
Below, we present this data in two ways. First, we present two tables, one for the tabulations tab year in Our data and one for tabulations in their data tab year.
To get a better sense of what these look like, we create visualizations, which are further explained below. These are instrumental in detecting what the underlying issue is.
All of the output is based off of the tab year command
in Stata. The goal is to have four snapshots of the data, first once all
of the data is loaded, second when the first major set of filters is
applied, third when observations are dropped if there is missing private
employment and fourth, right before saving the data-set. We label these
four snapshots “Snap-shot 1”, “Snap-shot 2”, “Snap-shot 3” and
“Snap-shot 4”, respectively.
All of the output is based off of the tab year command
in Stata. The goal is to have four snapshots of the data, first once all
of the data is loaded, second when the first major set of filters is
applied, third when observations are dropped if there is missing private
employment and fourth, right before saving the data-set. We label these
four snapshots “Snap-shot 1”, “Snap-shot 2”, “Snap-shot 3” and
“Snap-shot 4”, respectively. In the original paper, at snapshot 3, they
drop observations where either public or private employment statistics
are missing. We do not do this because we are only interested in
creating statistics. Therefore, let “Snap-shot 3” and “Snap-shot 4” be
snapshots of the original data while “Snap-shot 3 Alt” and “Snap-shot 4
Alt” refer to snapshots of the same lines when we only drop missing
private employment.
?(caption)
5.3.2 Visualizing snapshots (tab year)
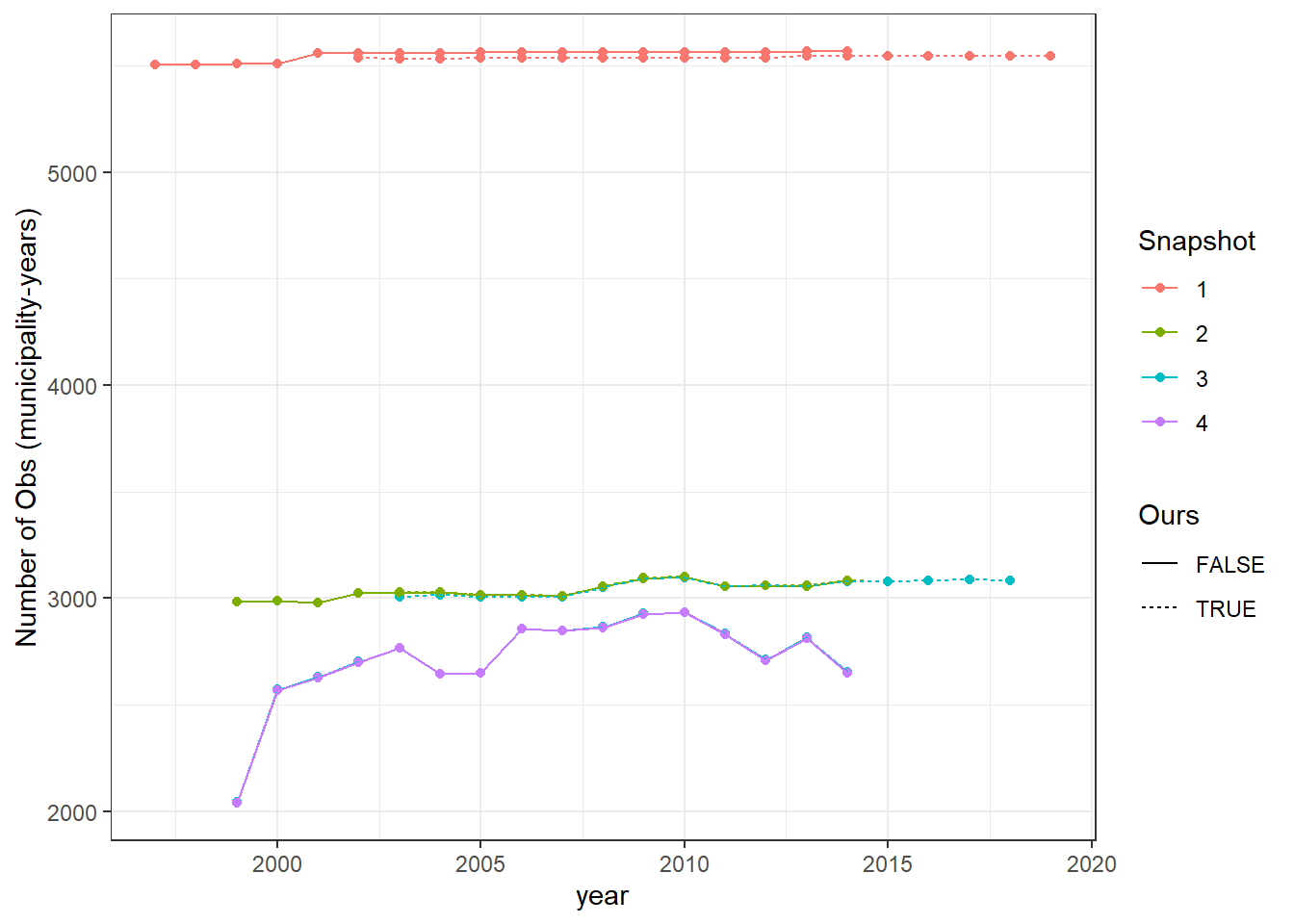
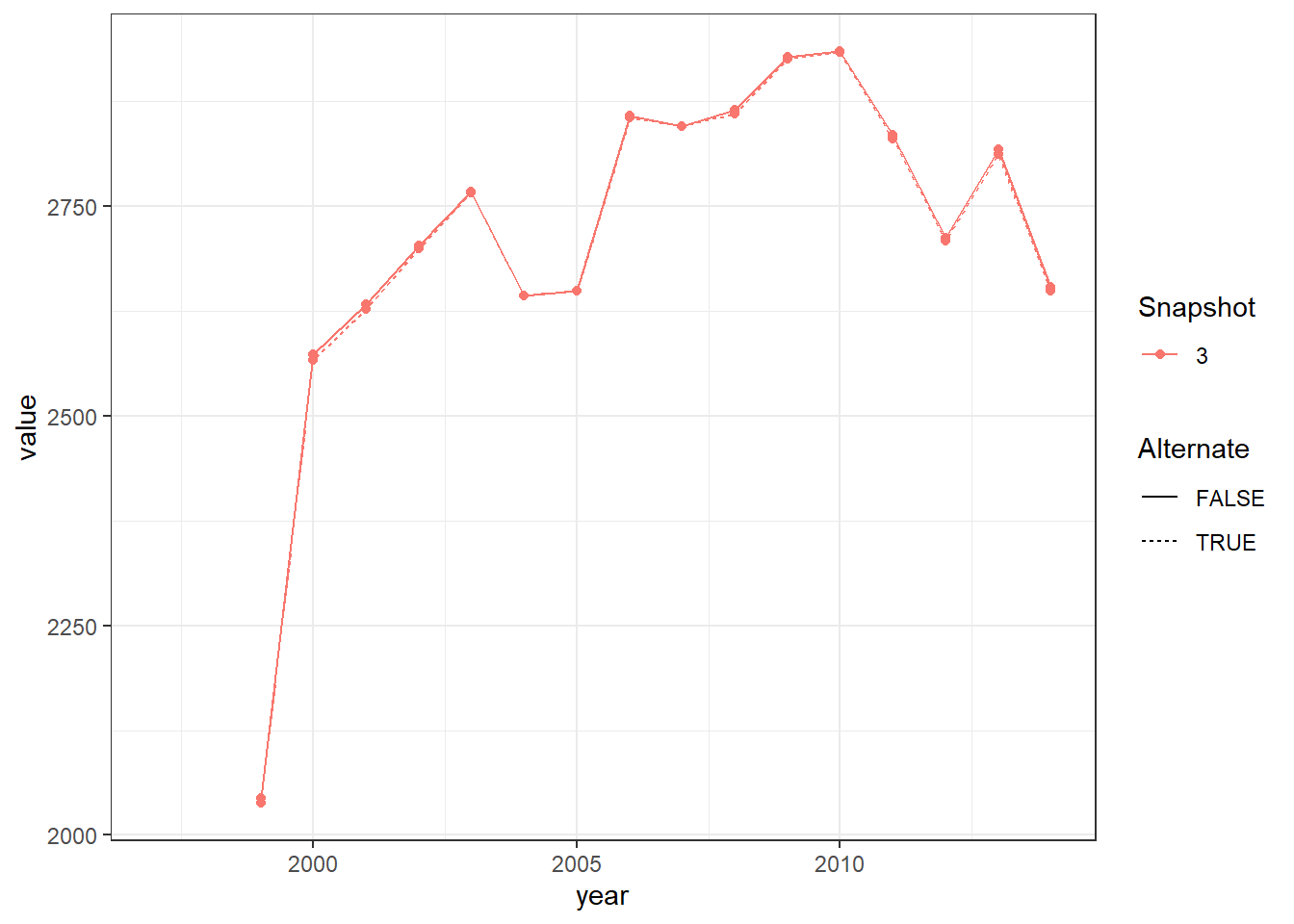
The Main Snap-shots figure illustrates that while at the first snapshot both data-sets have a similar number of observations, by snap-shot 4, they look exactly like the comparative statistics shown above (as expected). The Snapshot 1 figure illuatrates that there are some minor differences in the number of observations for the input data-sets. Snapshot 2 shows us that once the initial restrictions are applied, both data-sets are virutally identical in terms on numbers of observations. Since no observations are dropped between Snapshot 2 and the line of code which separates section Snapshot 3, it is pretty evident that this is where the differences in samples comes from, as the data-sets start taking on their final shapes. Snapshot 4 shows little to no difference from Snapshot 3.
In Snapshot 3, they drop all observations with missing public or private employment. Since we only require dropping missing private employment, we create figure Snapshot 3 - Alternate, which compares their data if they only drop missing private employment (like us) or drop both mossing public and private employment. The differences across data-sets is marginal. This leads us to question why they have so many missing labor market variables.
5.4 Why do they have so many missing labor markets?
In this section, we try to understand possible reasons as to why this data is missing.
Since this discovery was made while looking at Snapshots 2 and 3, we start off by probing a version of each data-set, taken from the end of snapshot 2, right before we drop the observations which show up in Snapshot 3.
The first analysis we perform on this data-set is to merge both data-sets on municipality-year and only keep the observations where one data-set has missing private employment (prin). We focus on missing prin because missing public sector employment pubn has been shown to only marginally alter their data-set.
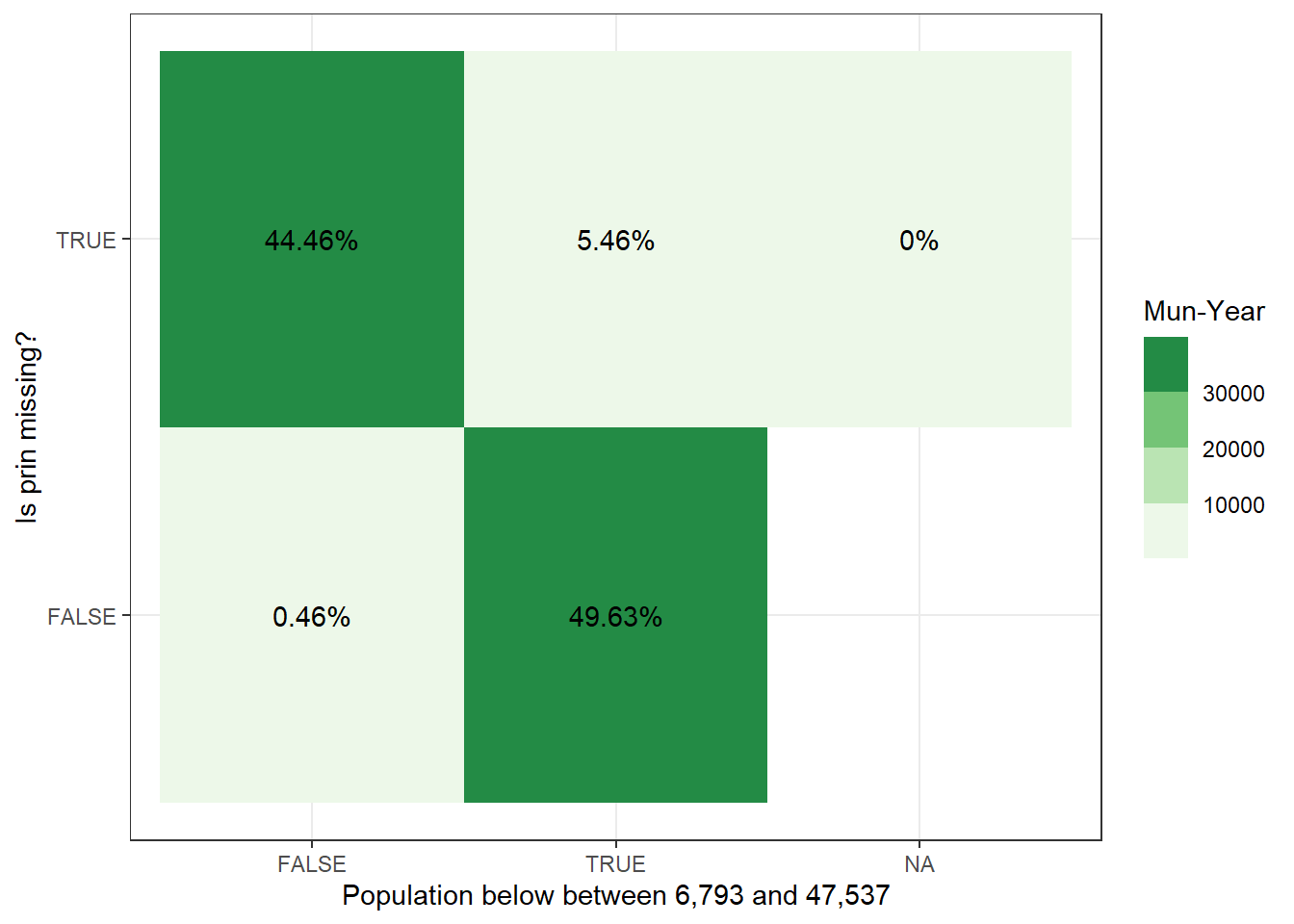
There is a clear difference in the quantity and quality of observations that they drop vs those which we drop. For starters, looking at Drop missing (prin) in THEIR data, there are 2697 observations which they have missing labor market data for but which we have ample data for.
Secondly, looking at Drop missing (prin) in OUR data, there are only 80 observations and despite most of the observations that are missing in our data, are also missing in their data. When we drop those that are also missing in their data, we are left with only 7 unique municipalities present in their data but not in ours (See table Missing Private Employment Summary).
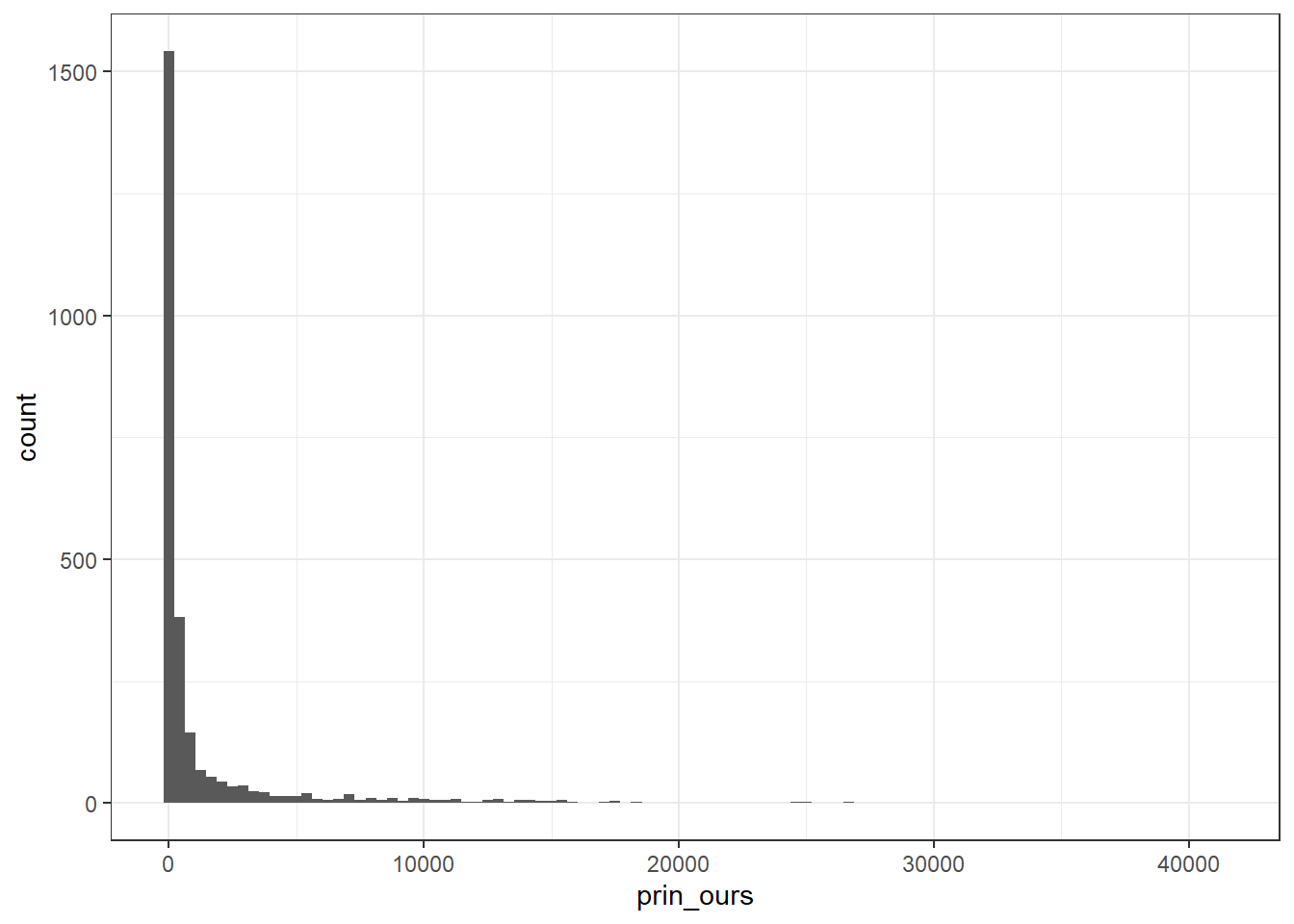
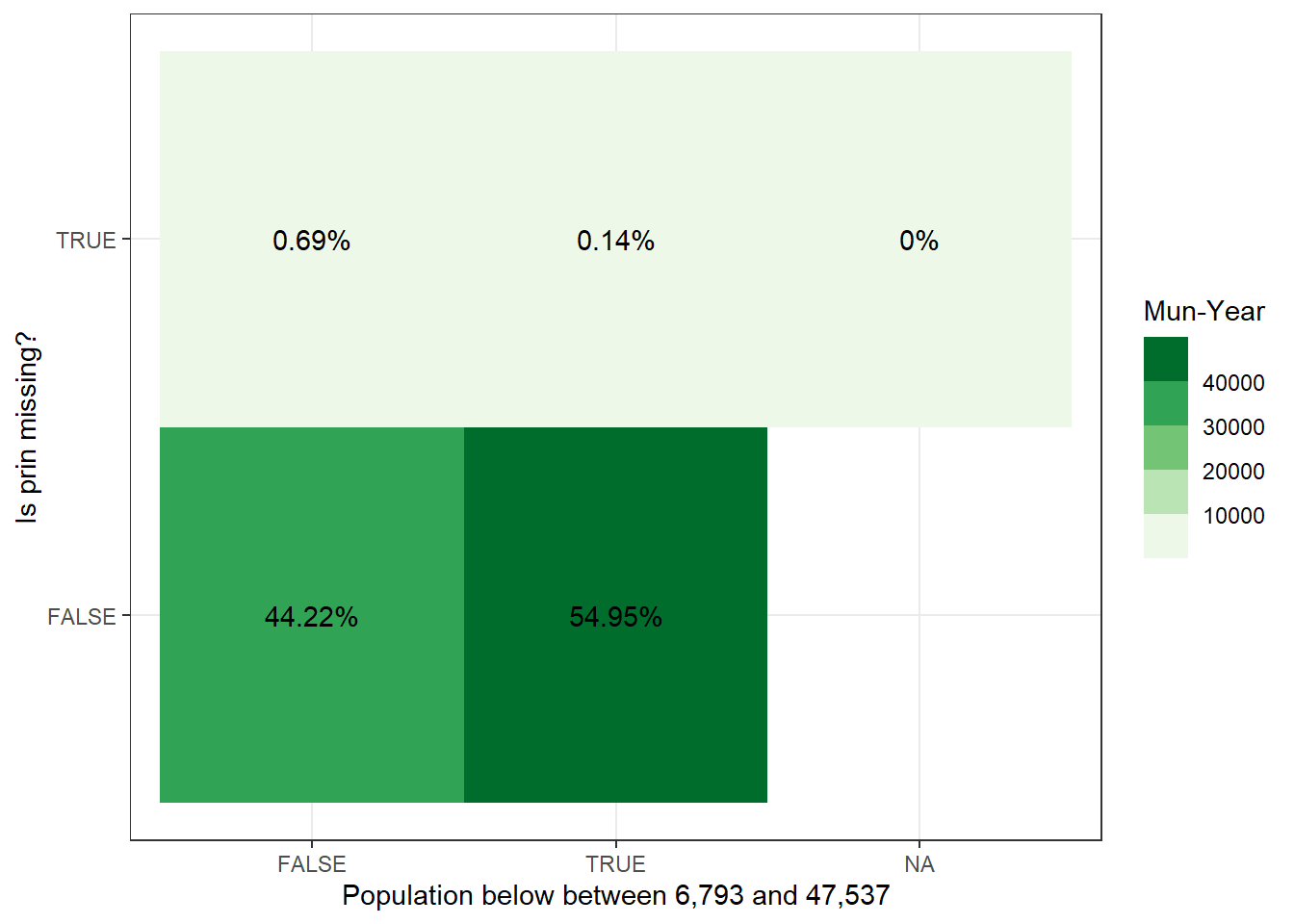
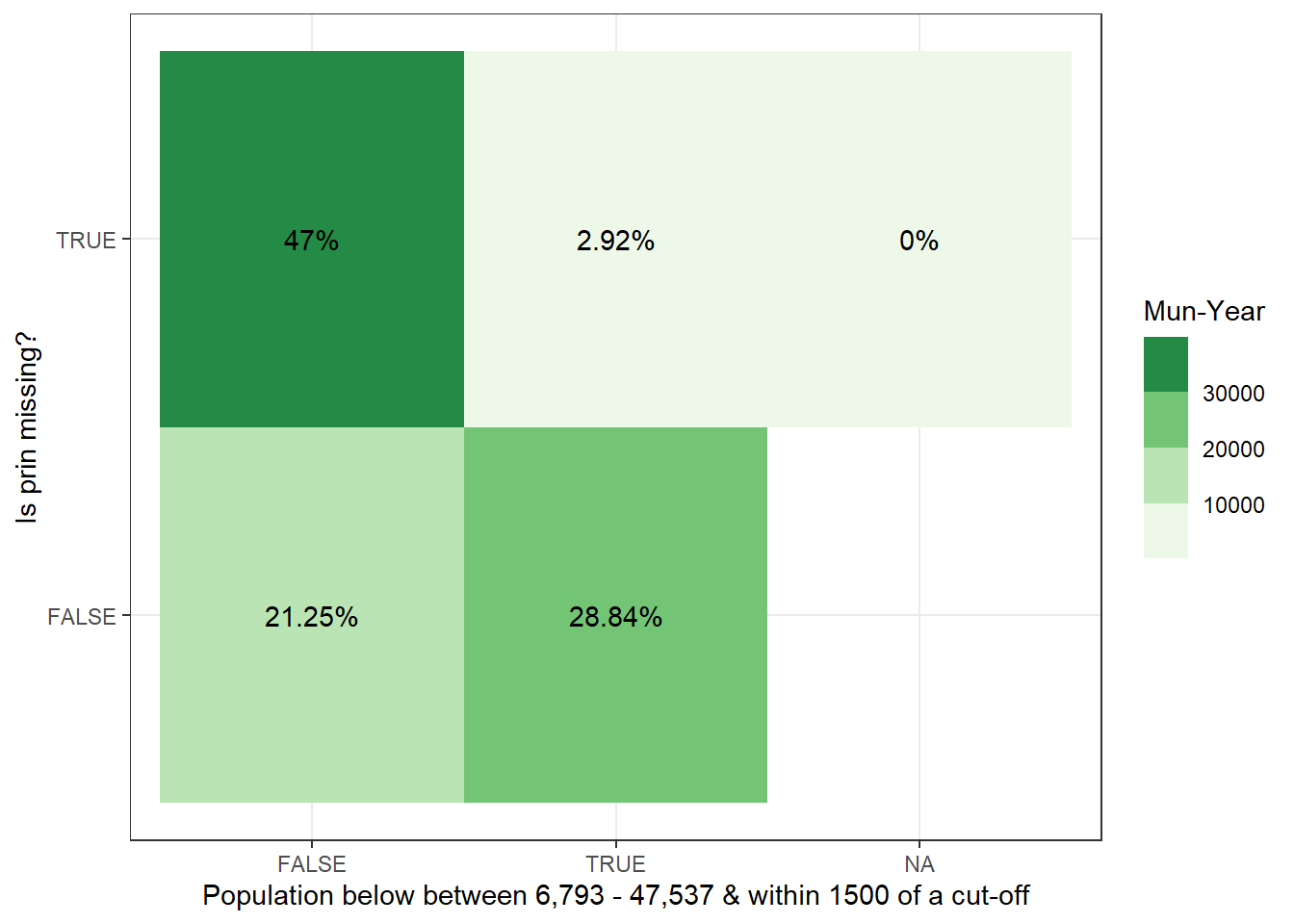
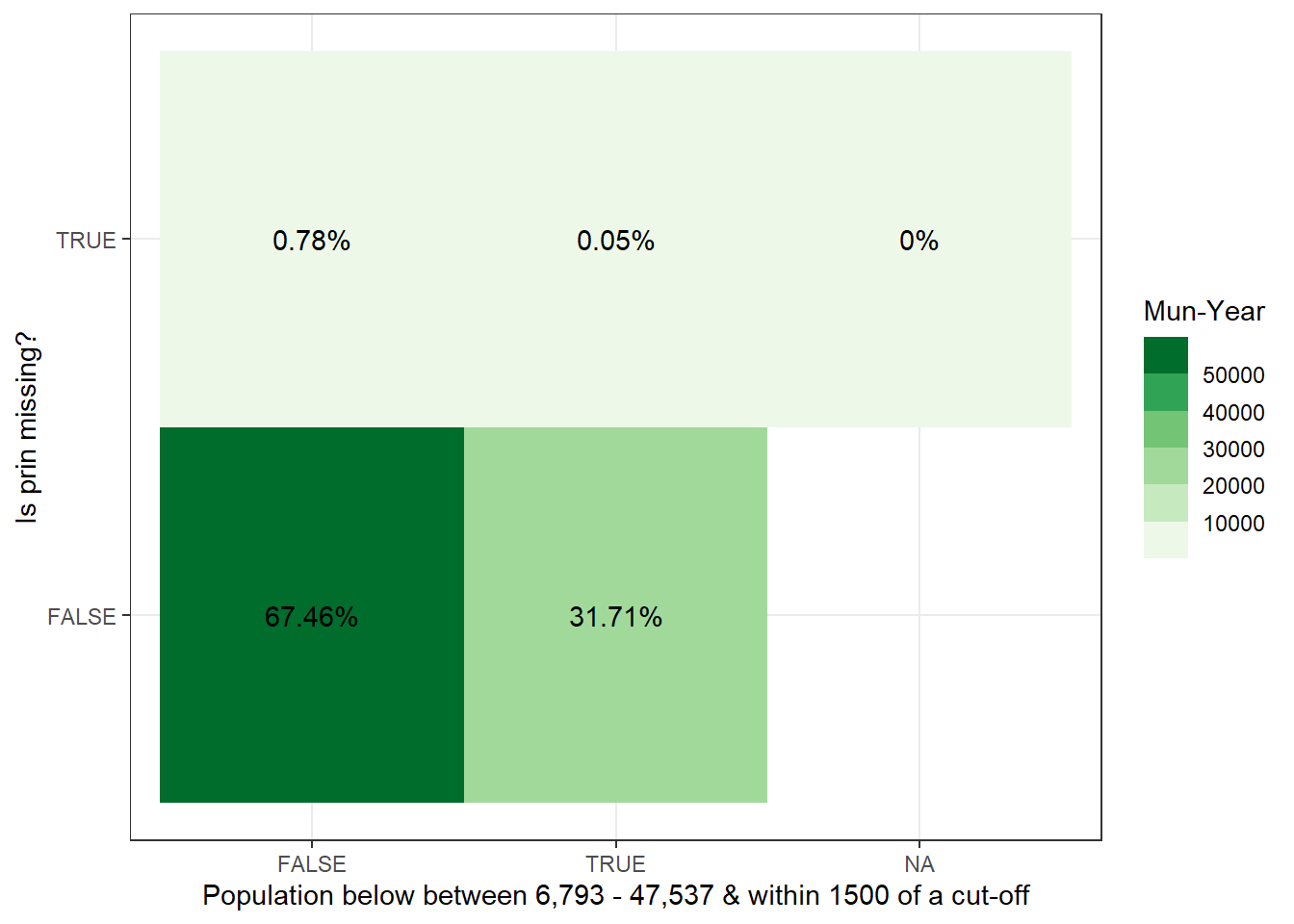
To test whether municipalities are not included because they have vrey few workers to begin with, we plot the distribution of private employment from our data for the municipalities where private employment is missing in theirs. As it turns out, two thirds of municipalities have less than 300 workers individuals, but this should be somewhat expected. What is alarming is that the distribution stretches far beyond this value. There is missing data for municipalities along the entire distribution private sector employment.
5.4.1 Looking at the data between Snapshot 2 and 3.
Code
# load data saved right before checkpoint 3 in THEIR data theirs_checkpointpre3 <- haven::read_dta(paste0(dir_transfers_replication, "data/processing/main_exact_data_checkpointpre3.dta")) %>%data.table() %>% .[, .(year, cod6, prin, prit, priw)] %>%rename_columns(current_names =c("prin", "prit", "priw"), new_names =c("prin_theirs", "prit_theirs", "priw_theirs") )# load data saved right before checkpoint 3 in OUR data ours_checkpointpre3 <- haven::read_dta(paste0(dir_transfers_replication, "data/processing/our_replication_data_for_figures_checkpointpre3.dta")) %>%data.table() %>% .[, .(year, cod6, prin, prit, priw)] %>%rename_columns(current_names =c("prin", "prit", "priw"), new_names =c("prin_ours", "prit_ours", "priw_ours") )# merge both data-sets between 2003-2013joint <-merge(theirs_checkpointpre3, ours_checkpointpre3, by =c("year", "cod6"), all=T) %>% .[(year>=2003)&(year<=2013)] # see what happens when we impose the `Checkpoint 3` drop missing data constraint (ONLY ON PRIVATE)joint_missing_in_theirs <-joint %>%copy() %>% .[is.na(prin_theirs)]# see what happens when we impose the `Checkpoint 3` drop missing data constraint (ONLY ON PRIVATE)joint_missing_in_ours <- joint %>%copy() %>% .[is.na(prin_ours)]
missing_in_theirs_1 <- joint_missing_in_theirs[, uniqueN(cod6)]missing_in_ours_1 <- joint_missing_in_ours[, uniqueN(cod6)]missing_in_theirs_2 <- joint_missing_in_theirs[!is.na(prin_ours)][, uniqueN(cod6)]missing_in_ours_2 <- joint_missing_in_ours[!is.na(prin_theirs)][, uniqueN(cod6)]data.table(Description =c("Unique Municipalities missing in Theirs","Unique Municipalities missing in Theirs, not missing in ours","Unique Municipalities missing in Ours", "Unique Municipalities missing in Ours, not missin in theirs"), Value =c(missing_in_theirs_1, missing_in_theirs_2, missing_in_ours_1, missing_in_ours_2))
Descriptive statistics about missing prin in both data-sets
5.4.2.1 At Snapshot 1, how different are the data-sets?
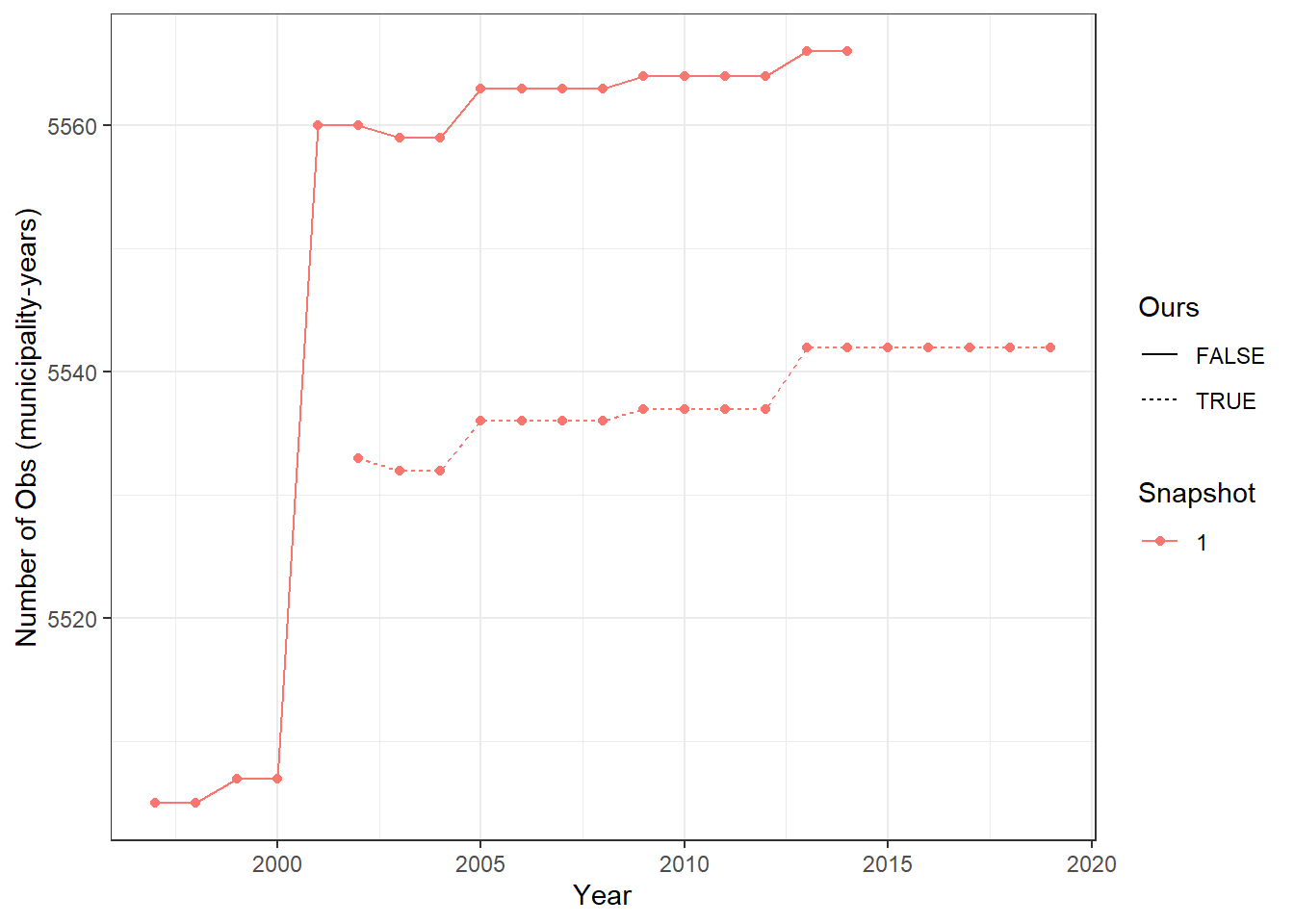
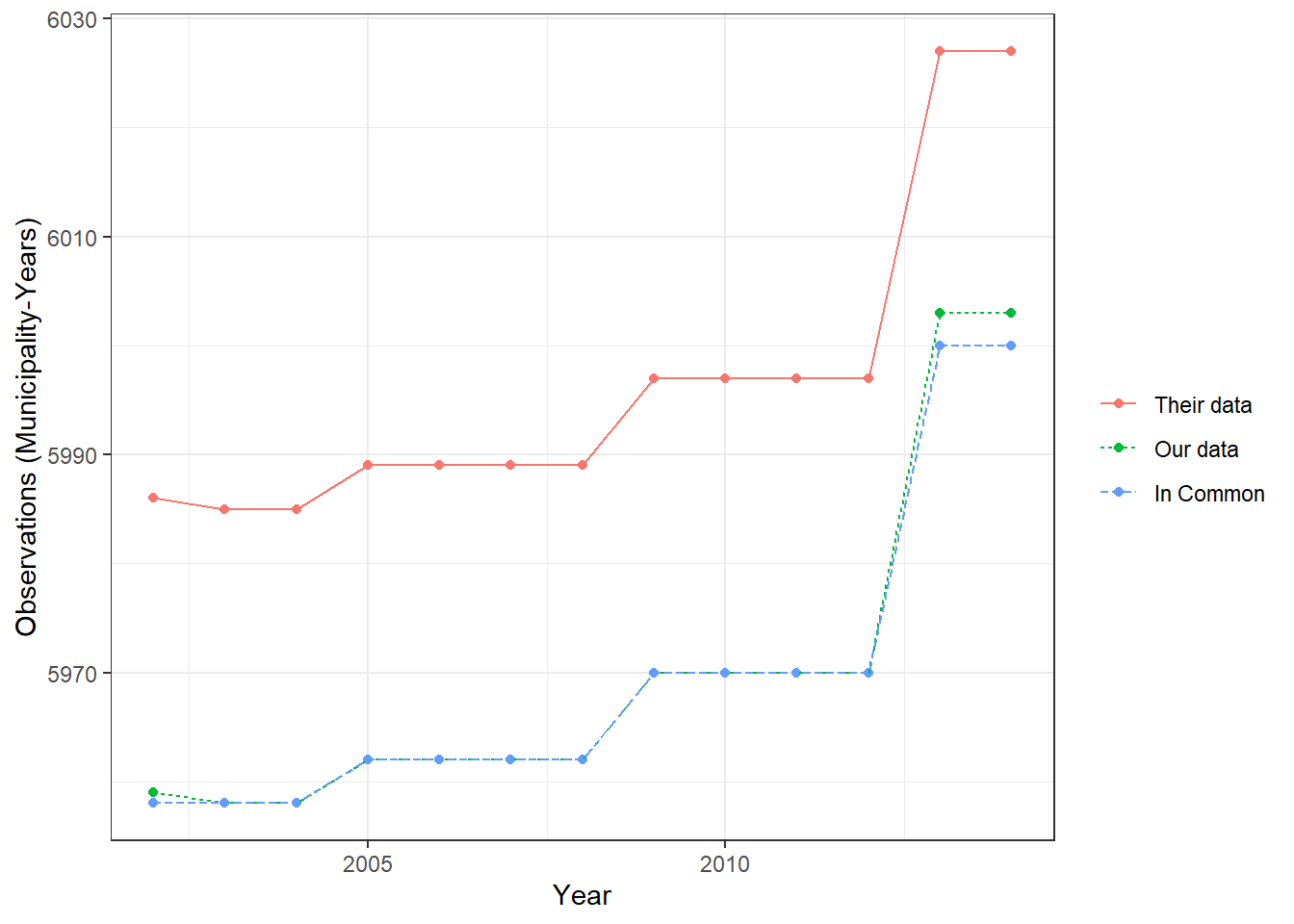
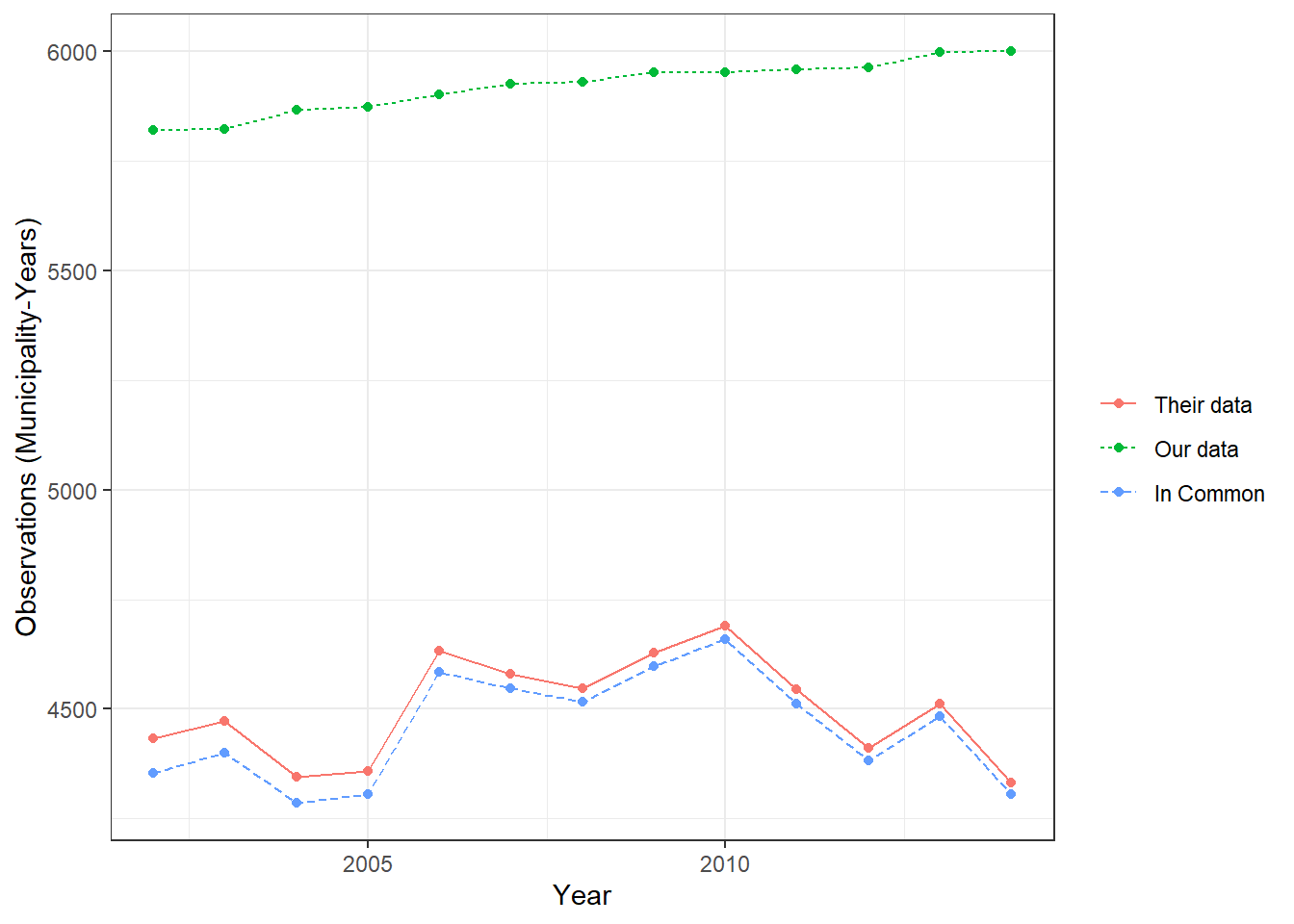
Figure 5.1 presents the number of observations in the input data-sets. Both data-sets are very similar in terms of number of observations. For the majority of the sample period (2002-2014), our municipality-years are completely contained within theirs. Despite this initial similarity in data-set size, in Figure 5.2 we observe that thei data-set has roughly 1500 less than ours when we remove missing prin from both data-sets.
(a) This figure presents the number of observations (municipality-years) in each data-set between 2002-2014 once all of the data is loaded in at Snapshot 1. Here, we see that they have roughly 30 more observations than we do at the start. Their/Our data refers to the municipality years in their/our data-sets. In Common referes to the municipality-years both data-sets share.
Figure 5.1: Snapshot 1) Observations common to both data-sets.
(a) This figure presents the number of observations (municipality-years) in each data-set between 2002-2014 once all of the data is loaded in at Snapshot 1 and observations with missing private employment (prin) are dropped. Here, we see that our data has roughly 1500 more observations theirs at the start. Their/Our data refers to the municipality years in their/our data-sets. In Common referes to the municipality-years with non-missing prin in both data-sets.
Figure 5.2: Snapshot 1) Observations common to both data-sets without missing Privae Employment.
In the first section of the cleaning file, the authors merge in two data-sets: RAIS_sectors.dta then RAIS_2digit.dta. In Table 5.1 and Table 5.2 we merge the two data-sets by municipality-year and show the number of missing observations present for each set of variables. Table 5.1 shows the number of missing observations for each data-set’s version of the prin variable and concludes that both data-sets have a very large number of missing prin, though RAIS_2digit.dta has 546 or so more. Meanwhile, Table 5.2 compares missing data for the prin_b10 and prin_b10_1 variables and highlights that the prin_b10 variable (and all other RAIS_sector variables) have consideraby more missing data.
Code
joint_RAIS %>% .[, .N, .(prin_sectors_missing=is.na(prin_sectors),prin_2digit_missing=is.na(prin_2digit))] %>%rename_columns(current_names =c("prin_sectors_missing", "prin_2digit_missing", "N"),new_names =c("Missing prin (RAIS_sectors)", "Missing prin (RAIS_2digit)", "Count") )
Table 5.1:
Comparing missing prin for RAIS_sector and RAIS_2digit input
data-sets