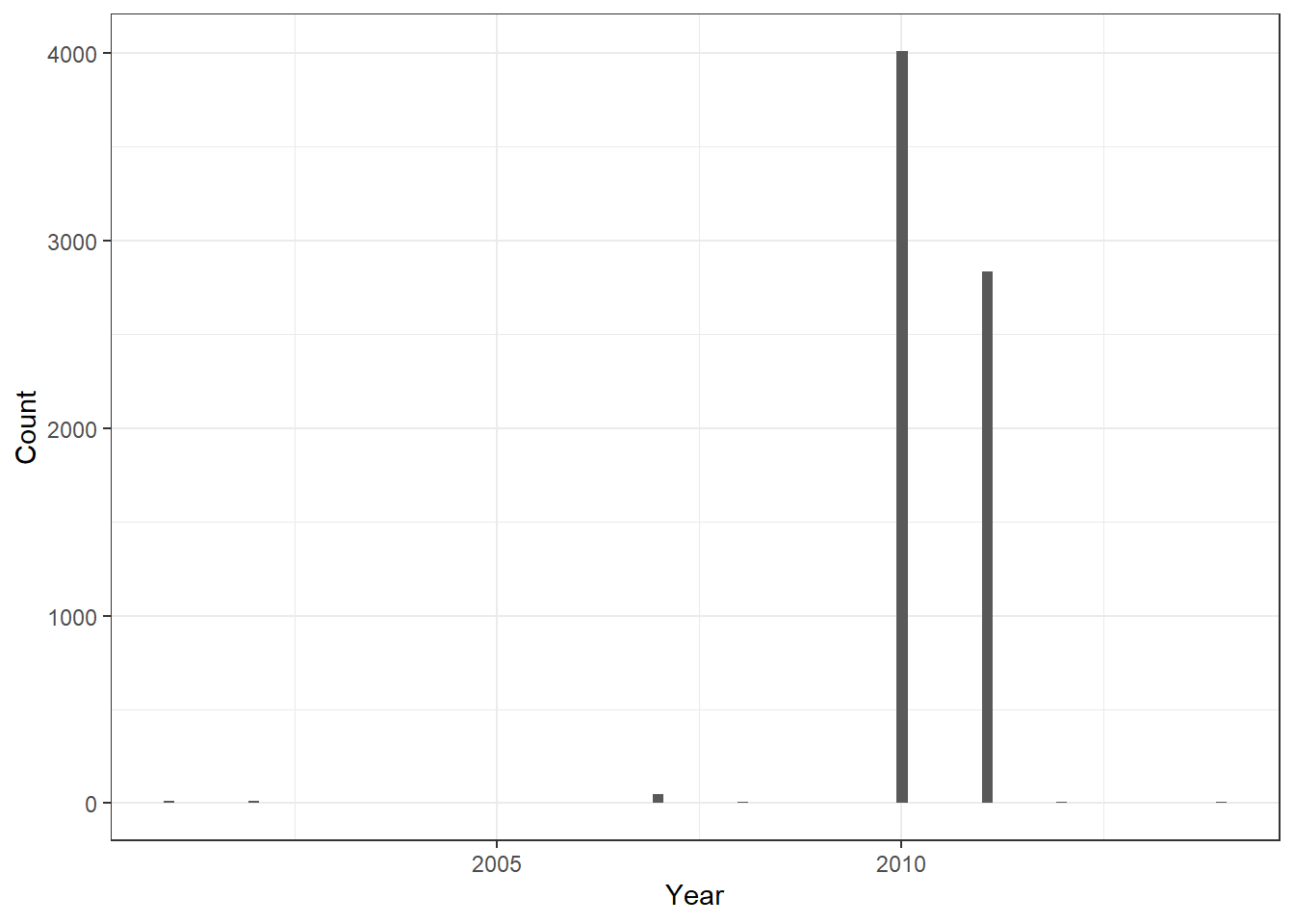In this page, we look at differences in the inputs which create theirs vs our figures. In Section 6.2 we investigate differences across population estimates. In Section 6.3 we investigate differences in the FPM transfers data-set; starting with the nominal FPM transfers (Section 6.3.1) then moving onto special cases which require 1997 data (Section 6.3.2). Lastly, we dive into differences in the labor market statistics.
The following table presents comparisons between our and their
population data-sets.
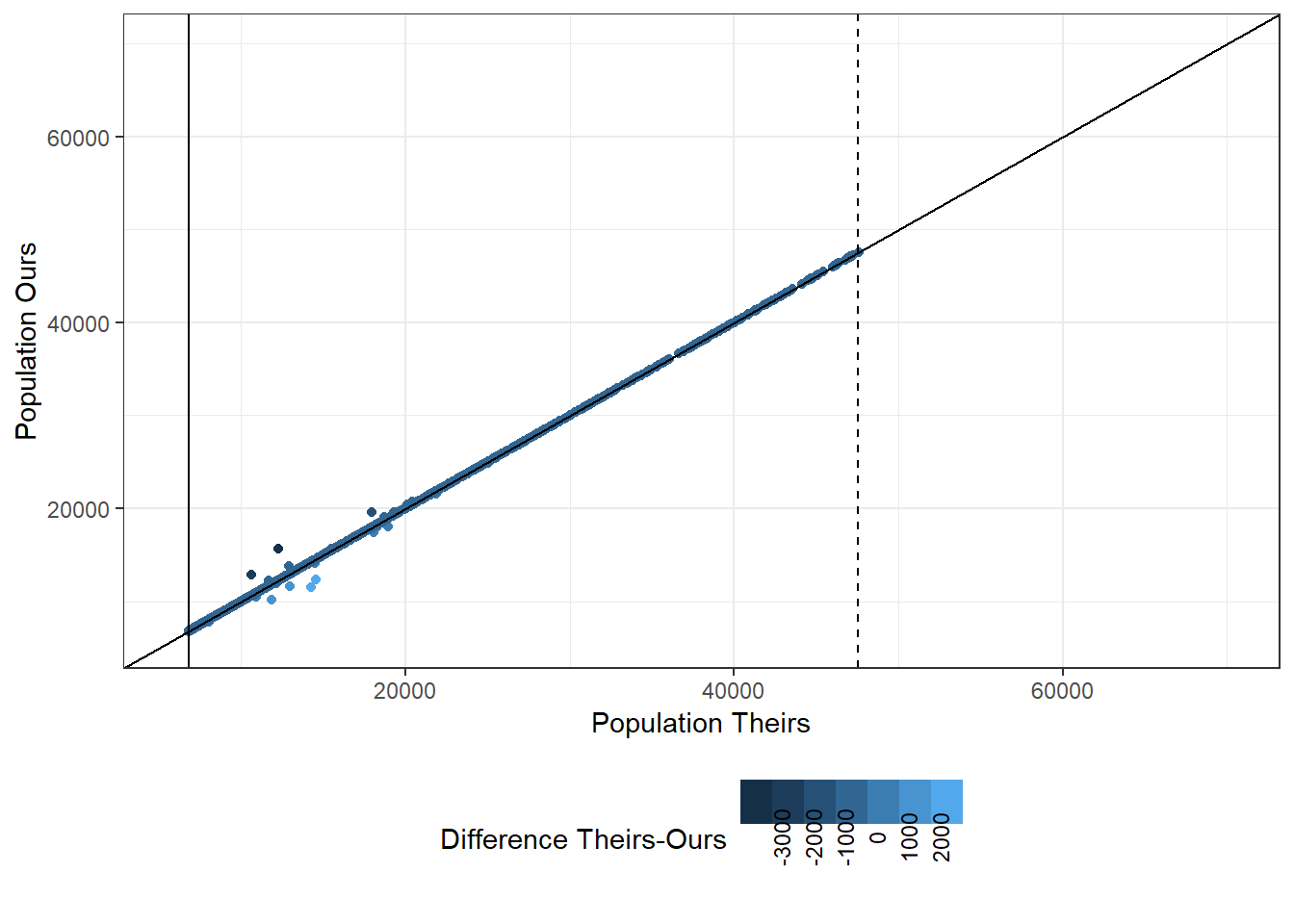
Of the 78,344 municipalities-years after 2000 available; both our and their data-sets share the same values for 70,566 municipality-years and differ (without counting missing data) across 6,943. While both data-sets share 437 missing municipalities, we have 392 additional missing municipality-years. Their data, on the other hand, has 6 missing municipality years.
6.2.2 Which municipalities are they missing?
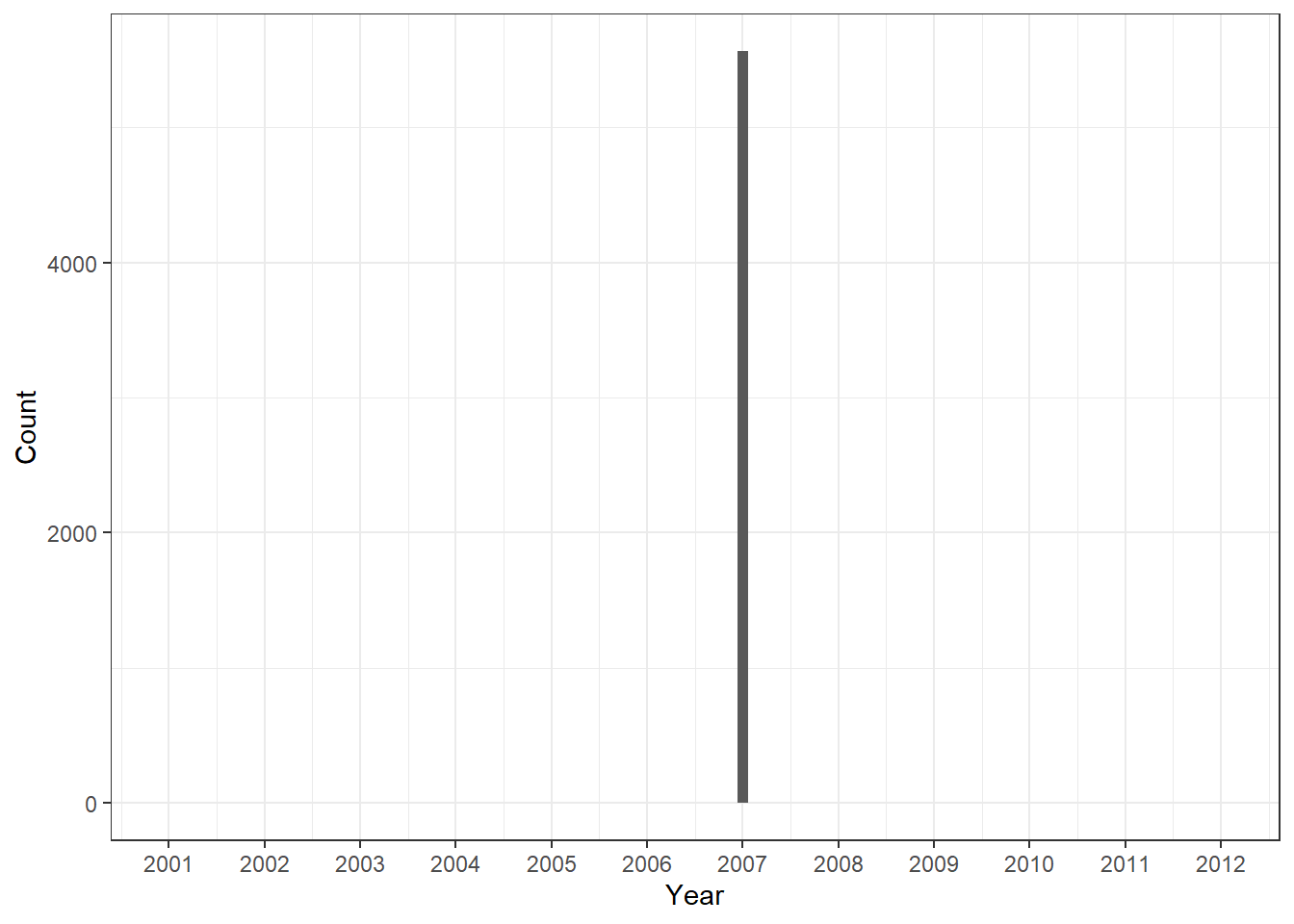
They are missing municipalities which were admittedly tricky to deal with when I cleaned the data but which we dealt with correctly and they didn’t. These 6 municipalities appear in the data-set in 2009 or 2013. Since we use the FPM transfer data with the original IBGE estimates available to the TCU in the year prior, rather than the IBGE population data, we were able to catch these.
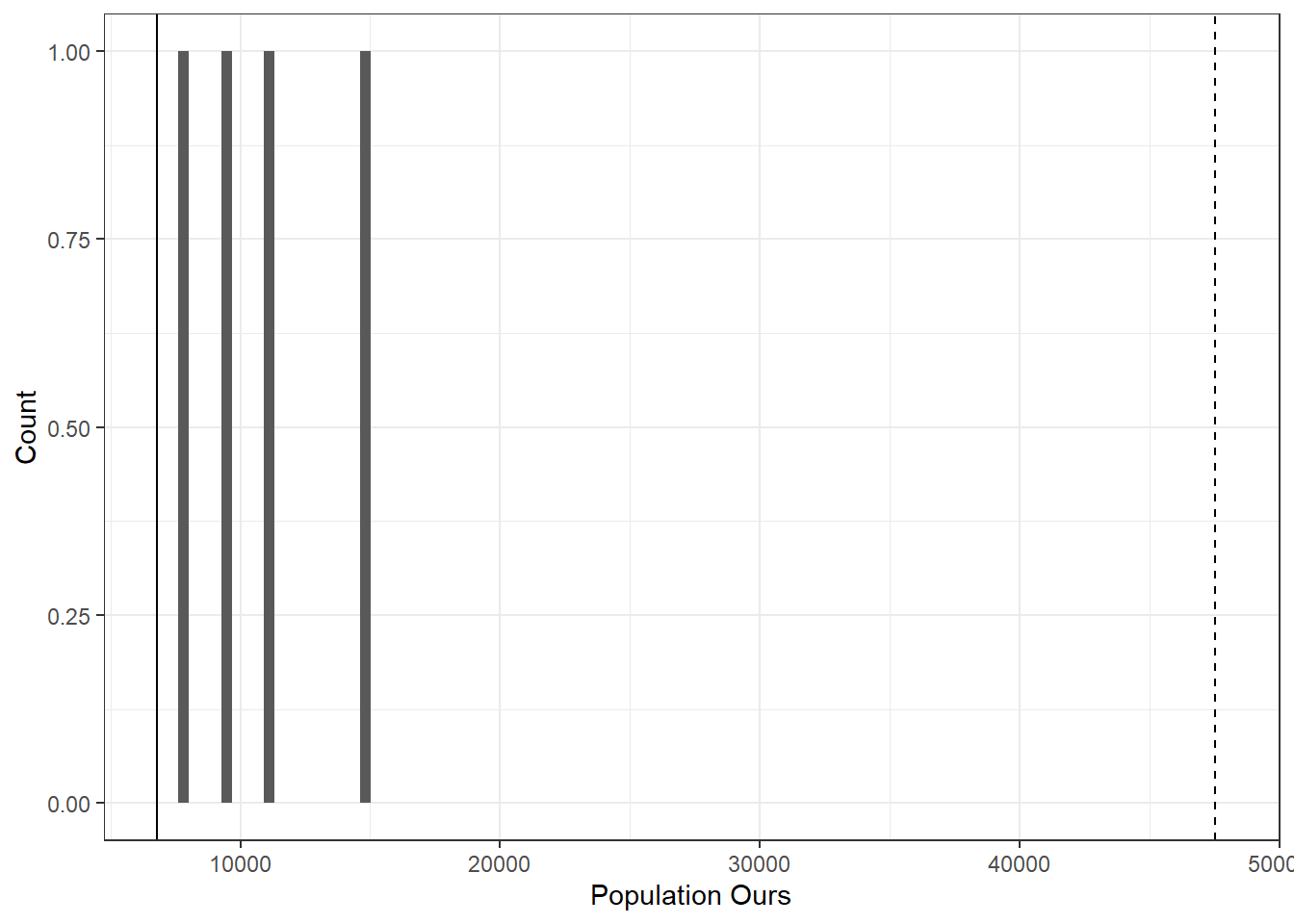
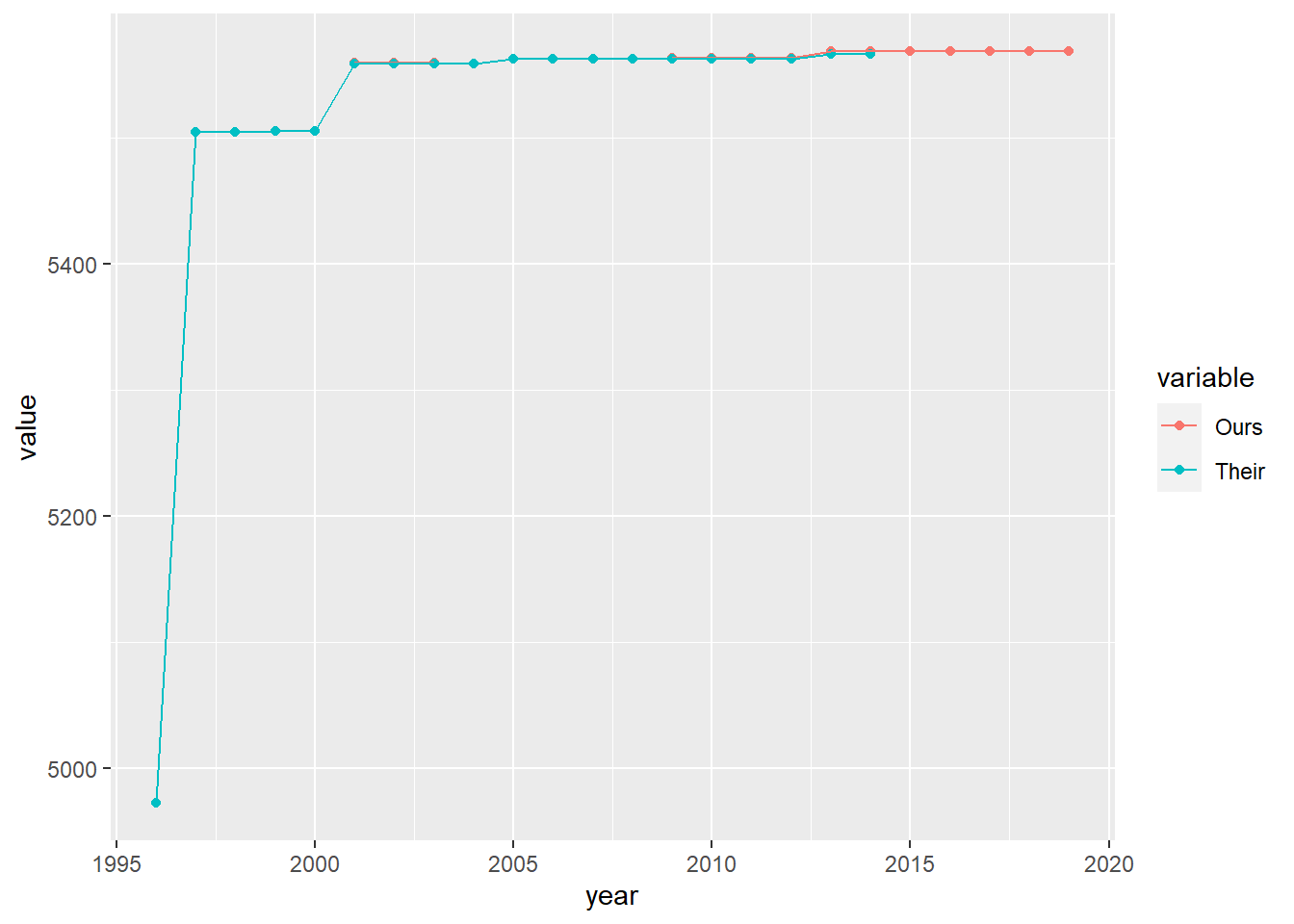
Figure 6.2: Population of missing municipality-years
Code
pop_our_present_theirs_missing %>%merge(ibge_info, . , by =c("cod6"), all.x=F, all.y=T)
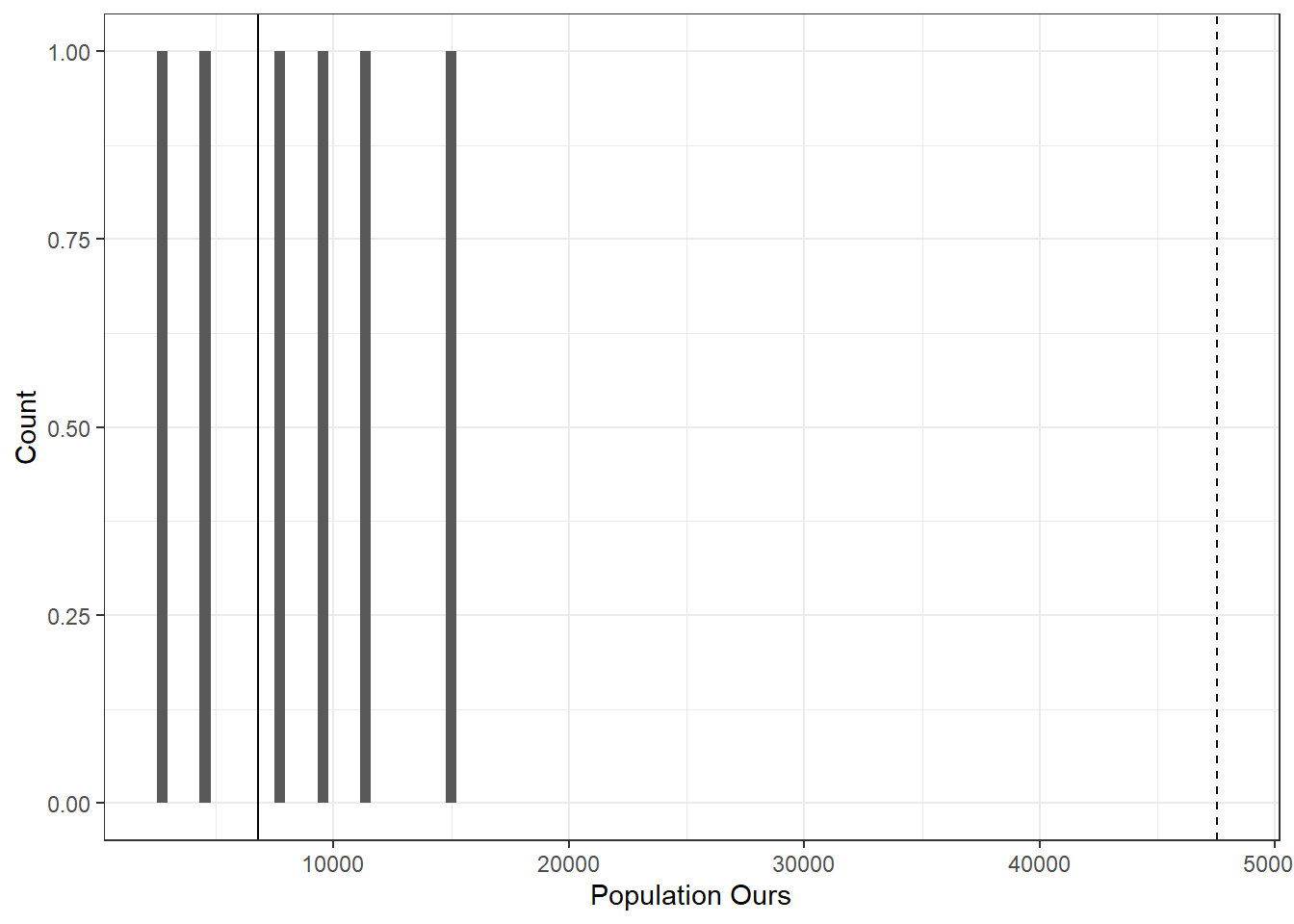
Figure 6.3: Population of missing municipality-years
6.2.3 Which municipalities are we missing?
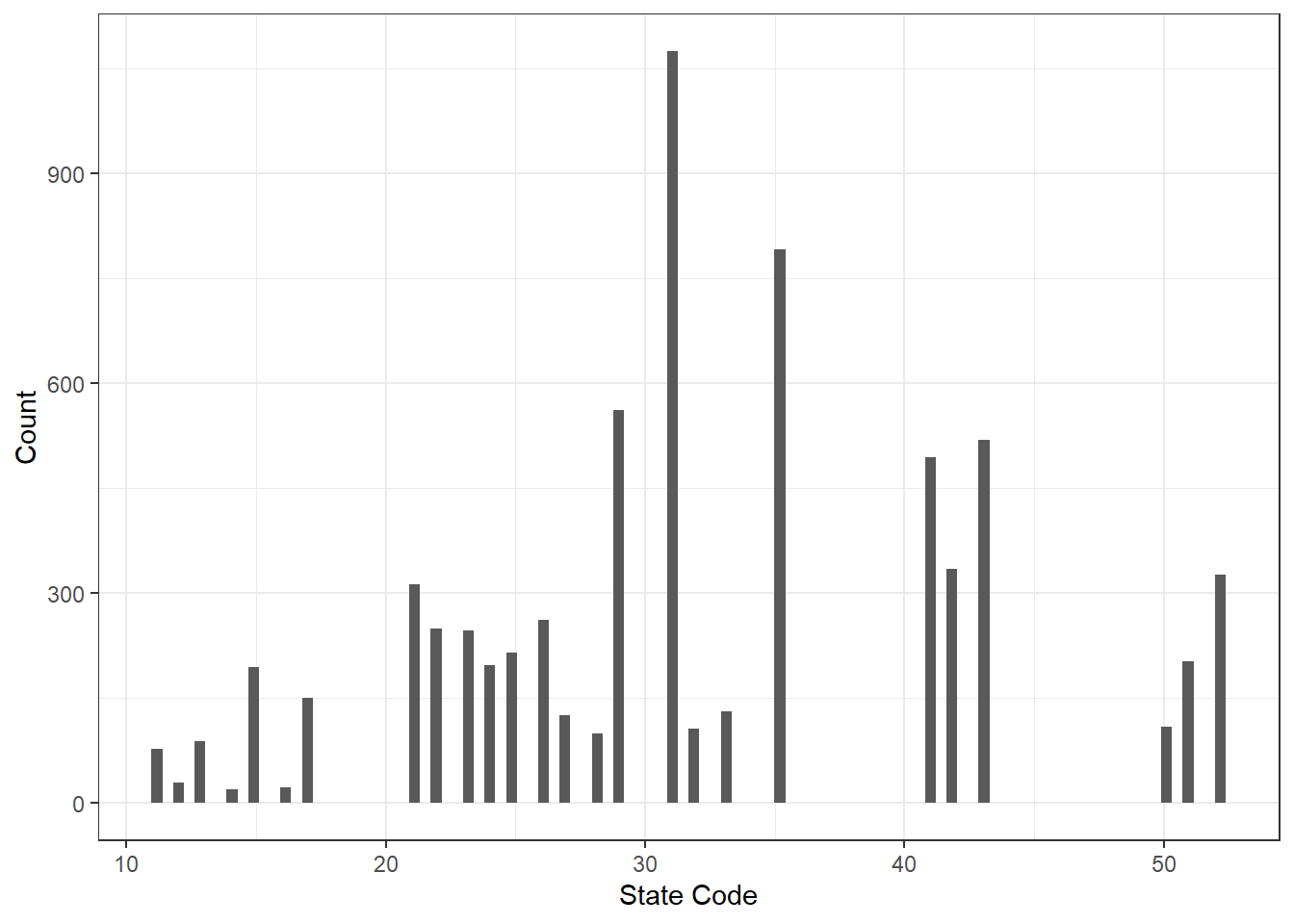
Figures Figure 6.4 and Figure 6.5 highlight that there are no municipalities within the analysis sample that have missing population data. Additionally, in our do file, we do not exclude observations that do not get merged, so premature dropping (which would impact total FPM computations) is not an issue for us.
Figure 6.5: Population of missing municipality-years
6.2.4 Which municipalities are missing in both?
Municipalities missing in both data-sets is partially an artifact of the data wrangling done below and has no impact in the final analysis. This occurs because there are some municipalities which appear and dissapear in the full panel. Below (Table 6.2) highlights these municipalities.
Additionally, there are some odd municipalities in their data-set which seemingly do not have any real world equivalents. (e.g. 159991) If this isn’t an error, then I would guess it is an old municipality code which does not exist.
6.2.5 Which municipalities are different but not missing?
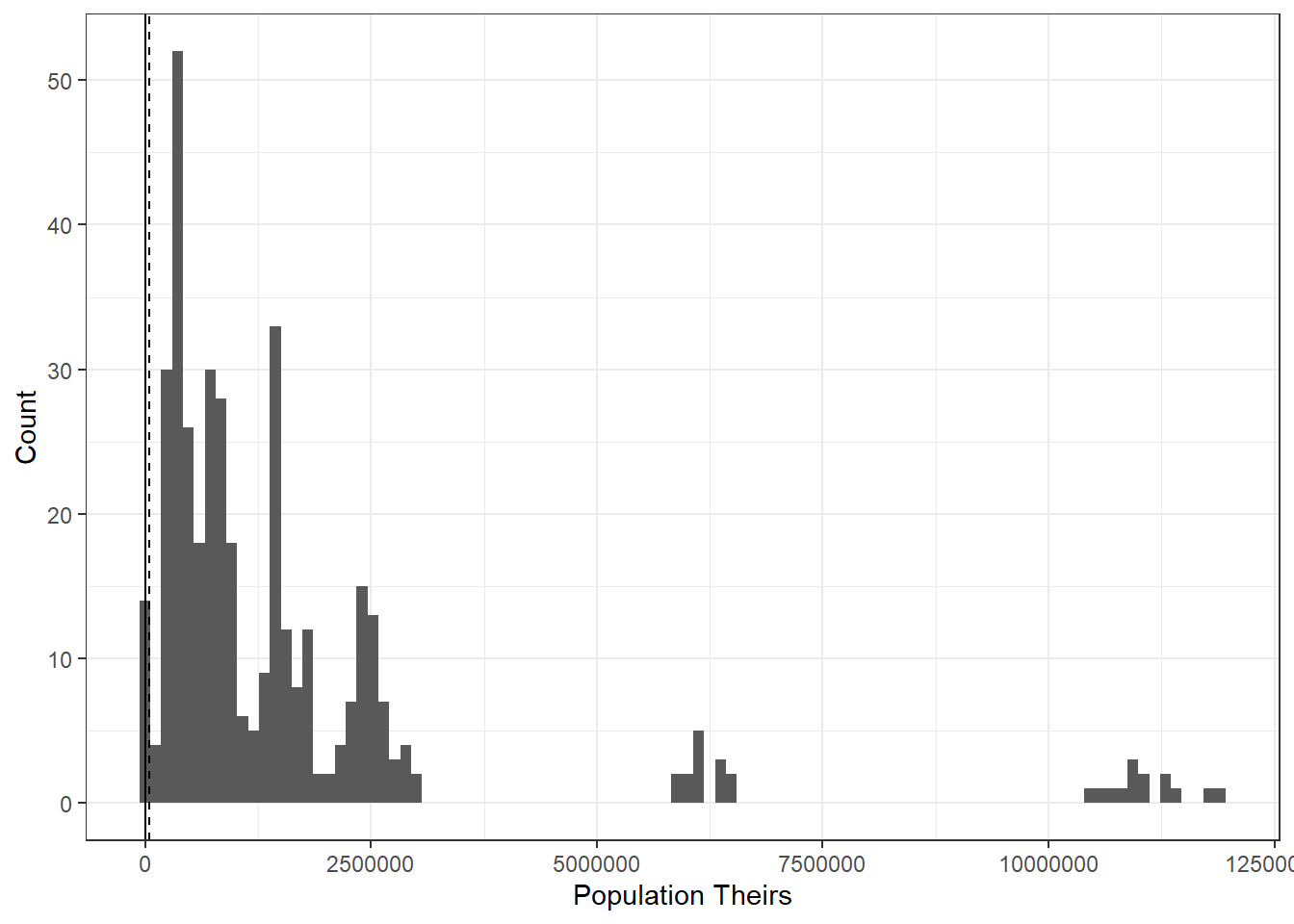
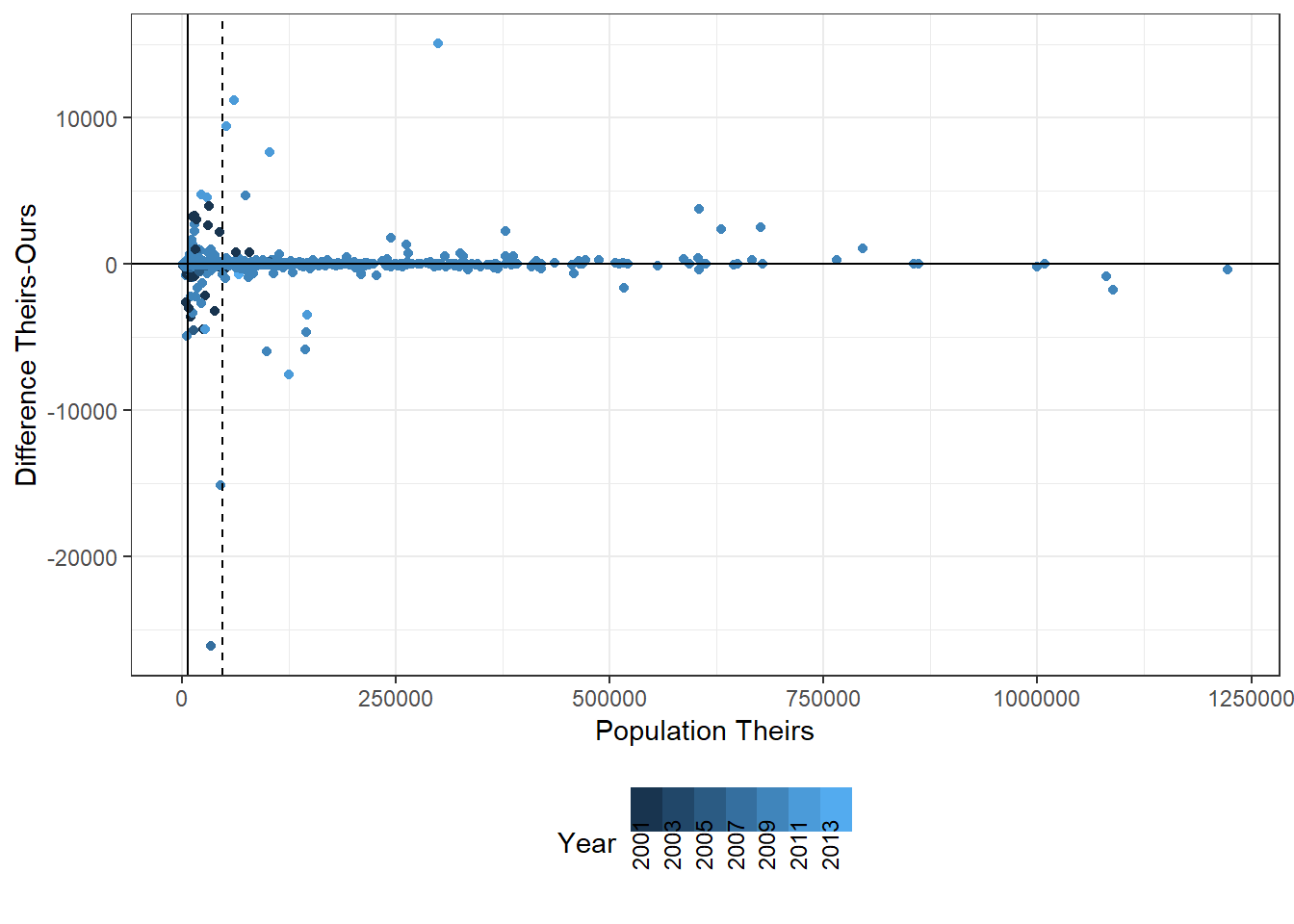
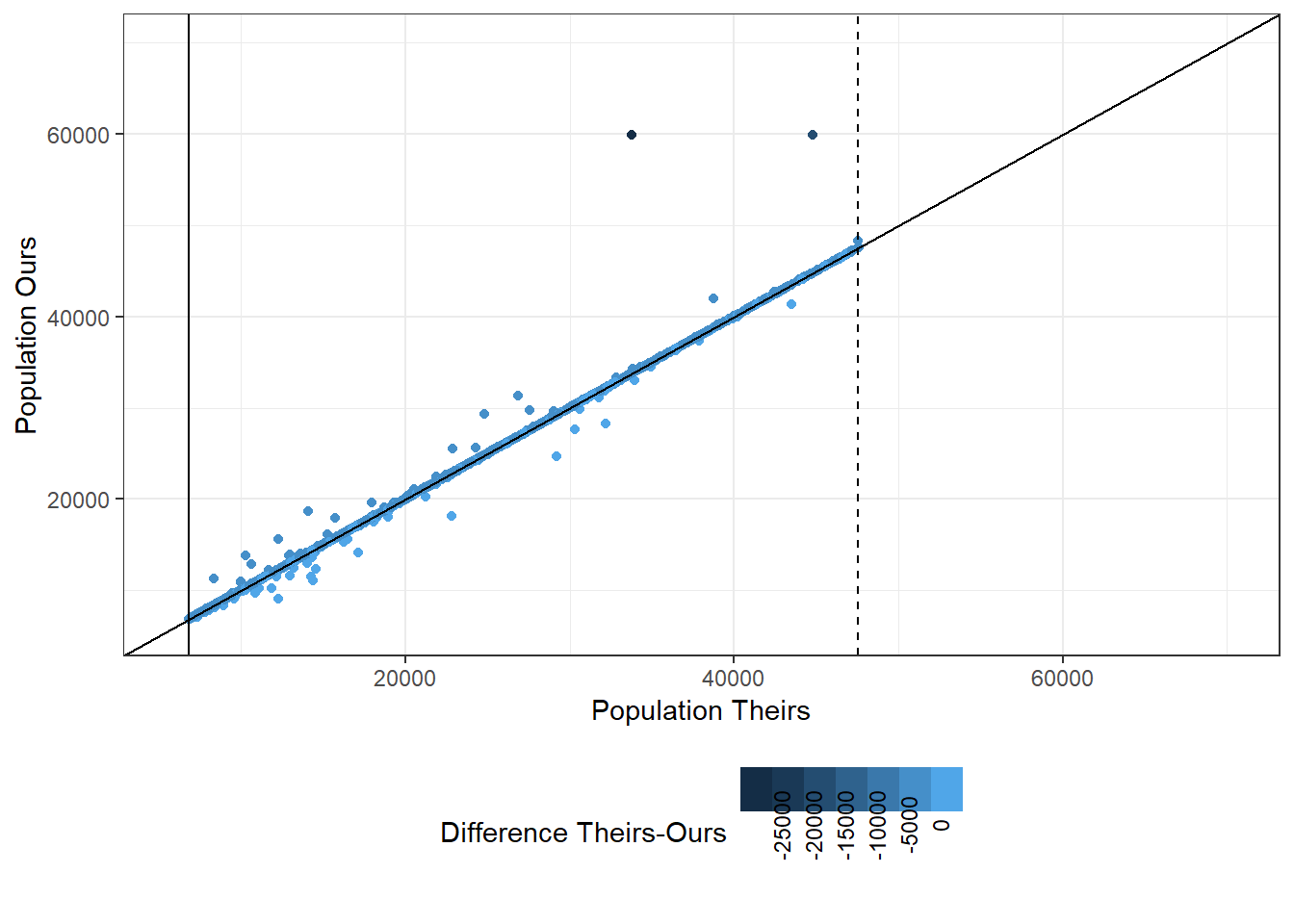
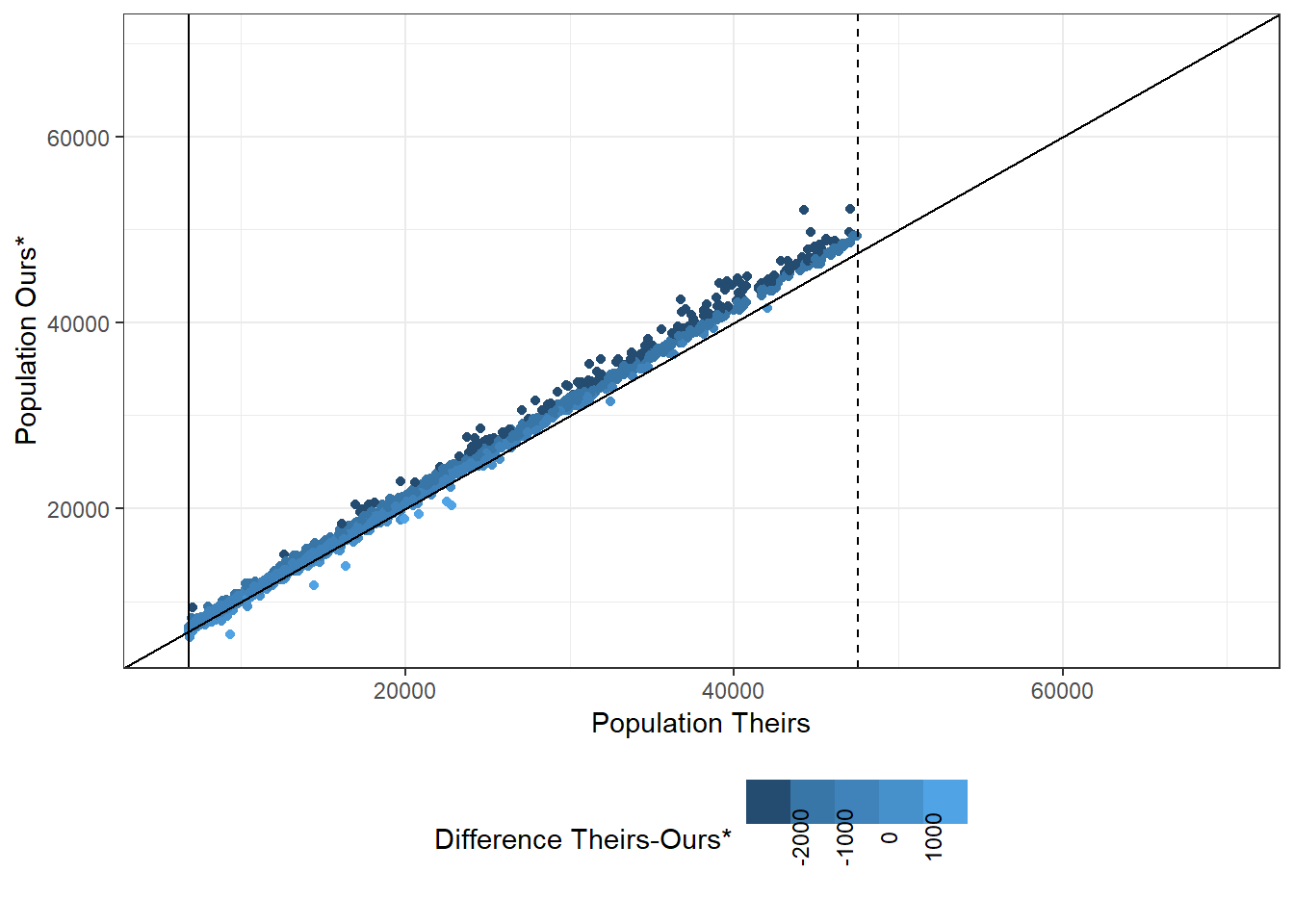
There are roughly 7,000 municipalities with mis-matching data. The issue occurs in all states but is mostly limited to 2010 and 2011. Most differences are relatively small, but they can extend up til 20,000 people.
Figure 6.10: Comparing Population Differences in 2011
6.2.6 What could explain these inconsistent municipalities?
First, as shown above, the deviation is both positive and negative and appears relatively symmetrical.
6.2.6.1 2010 has no official estimates online.
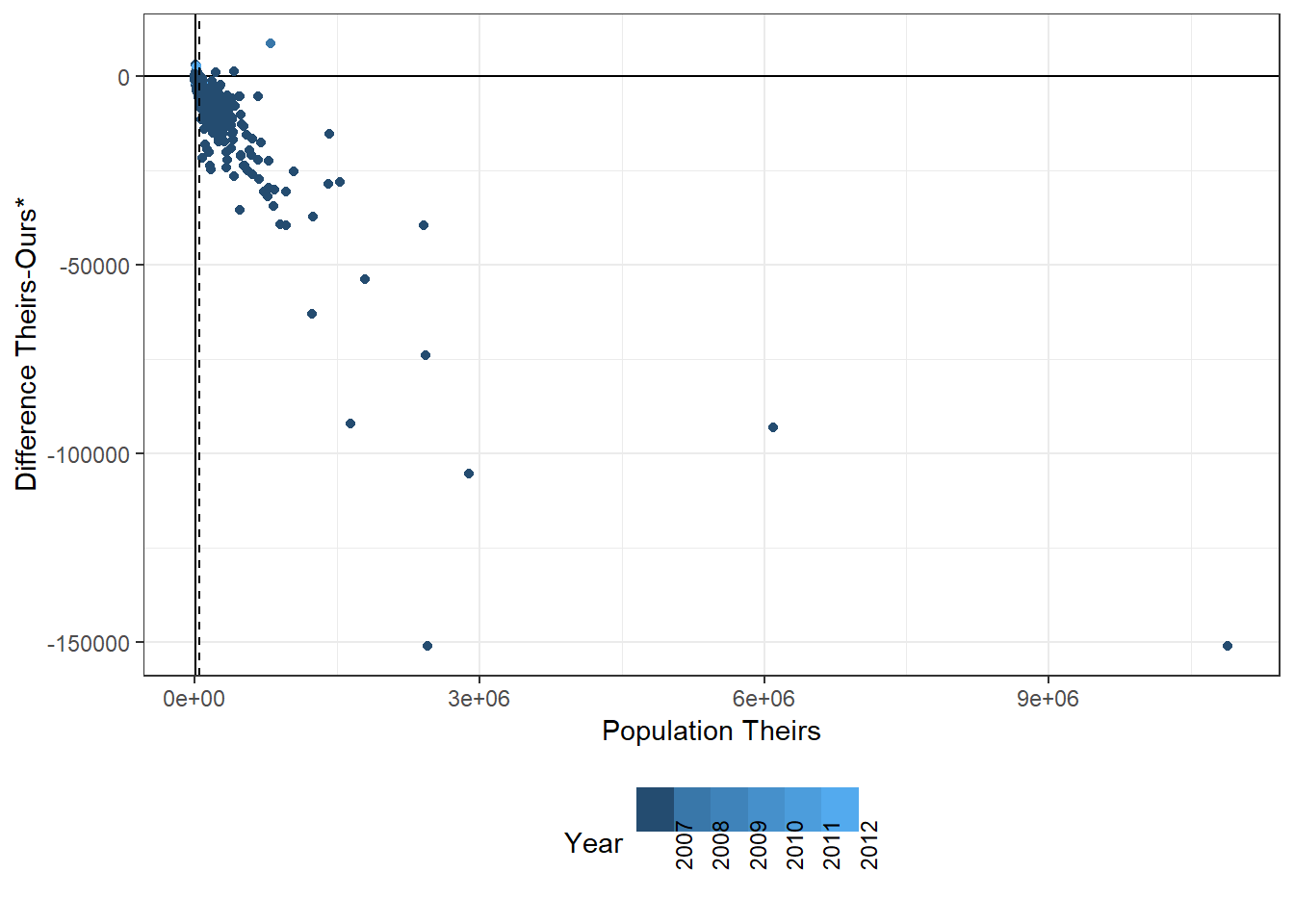
The reason for inconsistent estimates in 2010 is that there is no official estimates/documentation on the IBGE page for that year. Moreover, the authors do not state where exactly they source their data from, apart from stating it comes from IBGE. We checked the paper, the online appendix and the readme files and found no reference to this.
Our main data comes straight from the documentation used to compute the FPM coefficients, so it is bound to be the best source, at least in theory. When we check online, in say Wikipedia, which also cites IBGE without a clear link to the data, their estimates differ from ours and their as well: e.g. for cod6==110001 & year==2010, here are the following estimates for our, theirs and the Wikipedia figures: 24,422; 24,392 and 24,577.
We also clean data from the online web-page, but, as stated above, are missing estimates for 2010.
6.2.6.2 2011 illustrates their data comes from the same IBGE source we found
There is a perfect correlation between the IBGE data we found and cleaned online in the IBGE page and the author’s statistics. This implies that, beyond the primary sources data from the FPM documentation, our other IBGE data-set comes from the same source of data as theirs.
Code
# mere it inpop_not_ibge <- pop_not %>%merge(x=., y = ibge, by =c("cod6", "year"), all.x=T, all.y=F)# 2010 -----# no data for 2010# pop_not_ibge[year==2010][cod6==110001]# 2011 -----# pop_not_ibge %>%# .[year==2011] %>%# .[, cor(pop_est, popibge_theirs)]# pop_not_ibge %>%# .[year==2011] %>%# .[, cor(pop_est, popibge_ours)]
6.2.7 Is the alternate IBGE data we collected exactly like their data?
Yes, except we do not have 2010 data and 2007 has different estimates. Coincidentally, 2007 is the census year. We check to see if this is the source of the problems and discover that indeed it is. We went to the 2007 census webpage and downloaded the municipality level population data. We compare municipio==110001 & year==2007. Their estimate is consistent with the 2007 census estimate of 11,520; while our IBGE estimate is 12,241.
The following table presents comparisons between our and their
population data-sets.
6.2.7.1 Which municipalities are they missing?
Code
pop_our_present_theirs_missing2
Municipalities missing in their data but present in ours*
6.2.7.2 Which municipalities are we missing?
We are missing all of the 2010 municipalities because we were unable to find data for that year in the IBGE web-site.
Code
# pop_our_missing_theirs_present2
6.2.8 Which municipalities are missing in both?
Municipalities missing in both data-sets is an artifact of the data wrangling done below and has no impact in the final analysis. This occurs because there are some municipalities which appear and dissapear in the full panel. Below (Table 6.4) highlights these municipalities.
In this section, we compare their and our FPM data.
In terms of nominal yearly transfers, both data-sets appear to be consistent with one another. Minor differences in rounding lead to small differences in transfer estimates for 22% of all municipality-years. These differences are too small to matter. Additionally, differences in cleaning lead to two municipalities having a month’s worth of FPM transfers more in their data; because while we include negative FPM transfers in our computation, the authors omit them. All in all, the nominal municipality-year FPM transfers should not be a cause for concern and would not lead to the differences seen thus far in the replication.
First, we check both data-sets on the actual nominal fpm variable to determine whether there are any structural inconsistencies with the FPM data. In theory, we are aiming to have ALL municipalities the country for each year, because we require all available FPM transfers to compute the total yearly budget.
Our data-set spans 2001-2019 while theirs span 1996-2014. For the 2001-2019 period, there is a total of 77,895 unique municipality-years across both data-sets.
Shockingly, a large number of municipality-year fpm transfers are not equal across data-sets. As it turns out, these differences are a result of minor rounding erros and (in two cases) differences in how each research team handles negative transfers; we include them as they are while they replace negatives with NA. All in all though, there are no significant differences across the actual FPM transfers.
All of the mismatched data is a result of decisions taken when cleaning the data-set. The vast majority (99%) of mismatched data stems from rounding errors while the remaining few are a result of how each team cleans negative transfers. While they remove negative transfers from the yearly total, we include them. In ?tbl-sumstats_different_fpm, we present summary statistics for the differing data. In @
Below, we show that the two outlieRs are an artifact of the cleaning methodologies. The large differences for (Adamantina, SP) cod6==350010 & year==2001 and (Feira da Mata, BA) cod6==291077 & year=2004 are due to how each research team handles negative values in FPM data-set for specific months. It is unclear whether these should be positive values or whether they are analogous to refunds, but they are two minor edge cases and should not have a large impact on the final outcomes.
We detect inconsistent FPM transfers in their data-set (see Table 6.9). Namely, there are 10 matched observations which contain fpm transfer data but are not associated with a municipality cod6. Five of these correspond to actual municipality-years. Given how few there are, we do not investigate much further beyond explaining how to back track the municipality codes for these observations.
Despite not having associated municipality codes, we are able to associate the FPM transfers from their data to the state-year it belongs to and could even try to piece together what municipality has incorrect missing data. Each state-year’s FPM lump-sum is a function of federal tax revenues and each state’s fixed-share of the total FPM amount is unique. Additionally, all municipalities in a state-year within the same population bounds, will be assigned the same interior FPM amount. This logic breaks down only if the municipality in question also recieves reserve transfers. Therefore, we can assume that every state-year’s FPM lumpsum is unique, all municipalities with the same interior coefficient receive the same transfer and can thus infer which state-year-population bucket their missing data comes from.
For instance, below we show how we were able to determine that the missing observation for 2001 with an FPM transfer (their estimate) of 1,194,582.2 BRL was actually municipality cod6==431454. This is the only municipality with this same amount of transfers in 2001 missing in their data but present in ours.
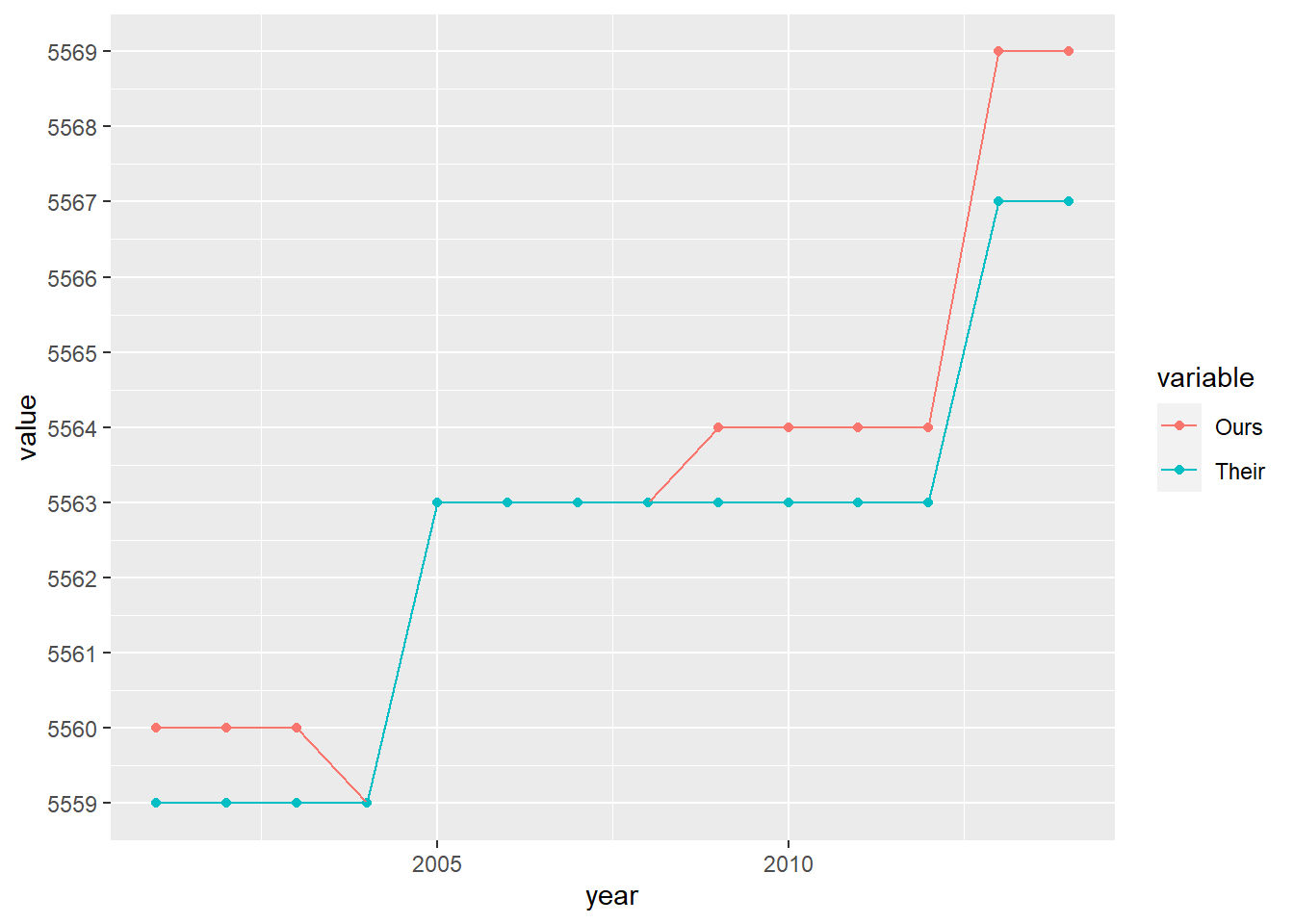
Table 6.10 highlights that there is a large number of observations whose 1997 coefficients do not match up. That said, this could simply be the result of not having 1997 coefficients for municipality-years that are not special cases. We test this in Table 6.12 and Table 6.13. Table 6.12 looks at observations between 2001-2007 which we categorize as being special cases. Of the 8908 municipality-years that are special cases, 578 (6%) have missing data. Conversely, Table 6.13 shows 2,062 of 24,297 municipality-years which are not special cases have the 1997 coefficient.
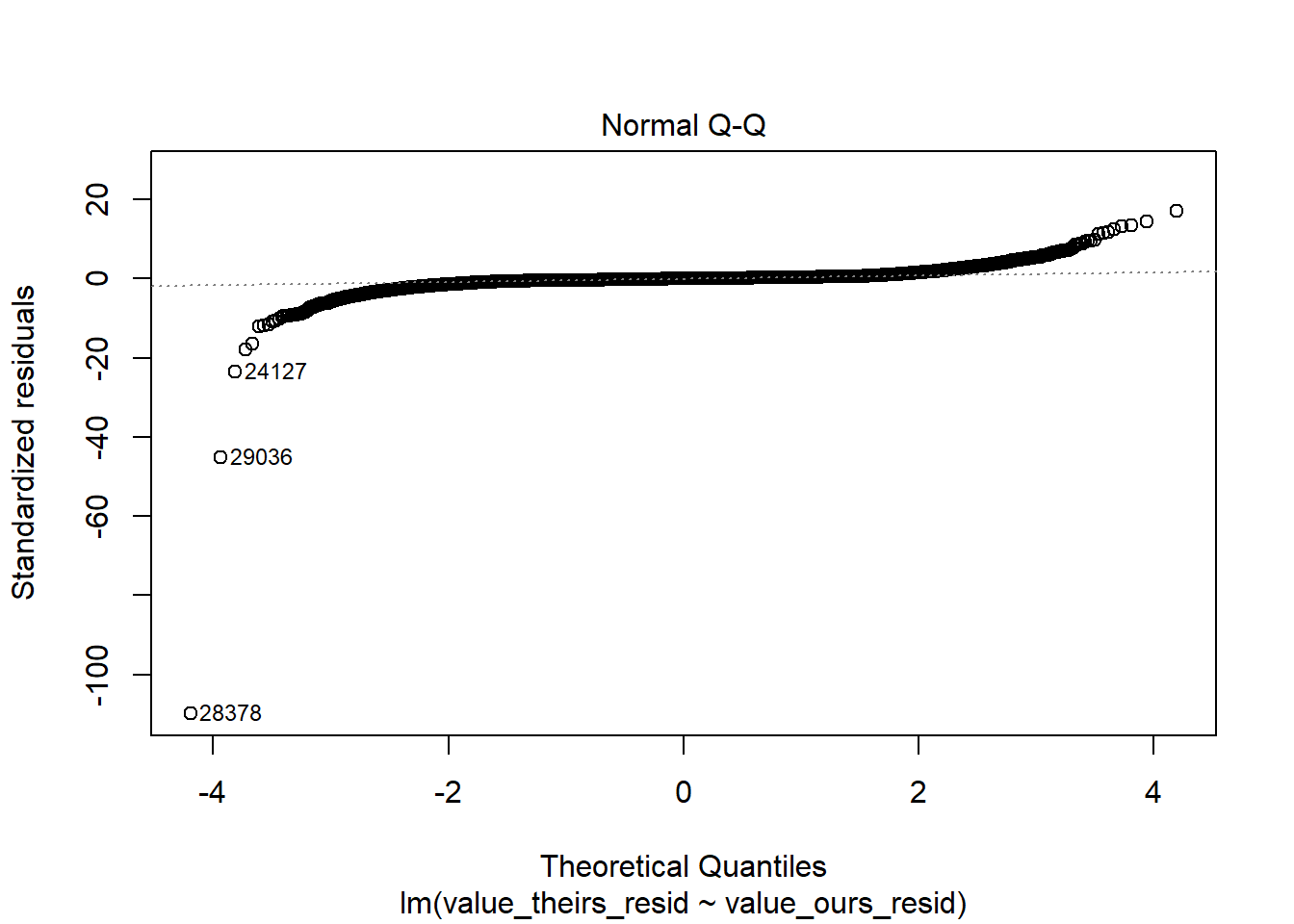
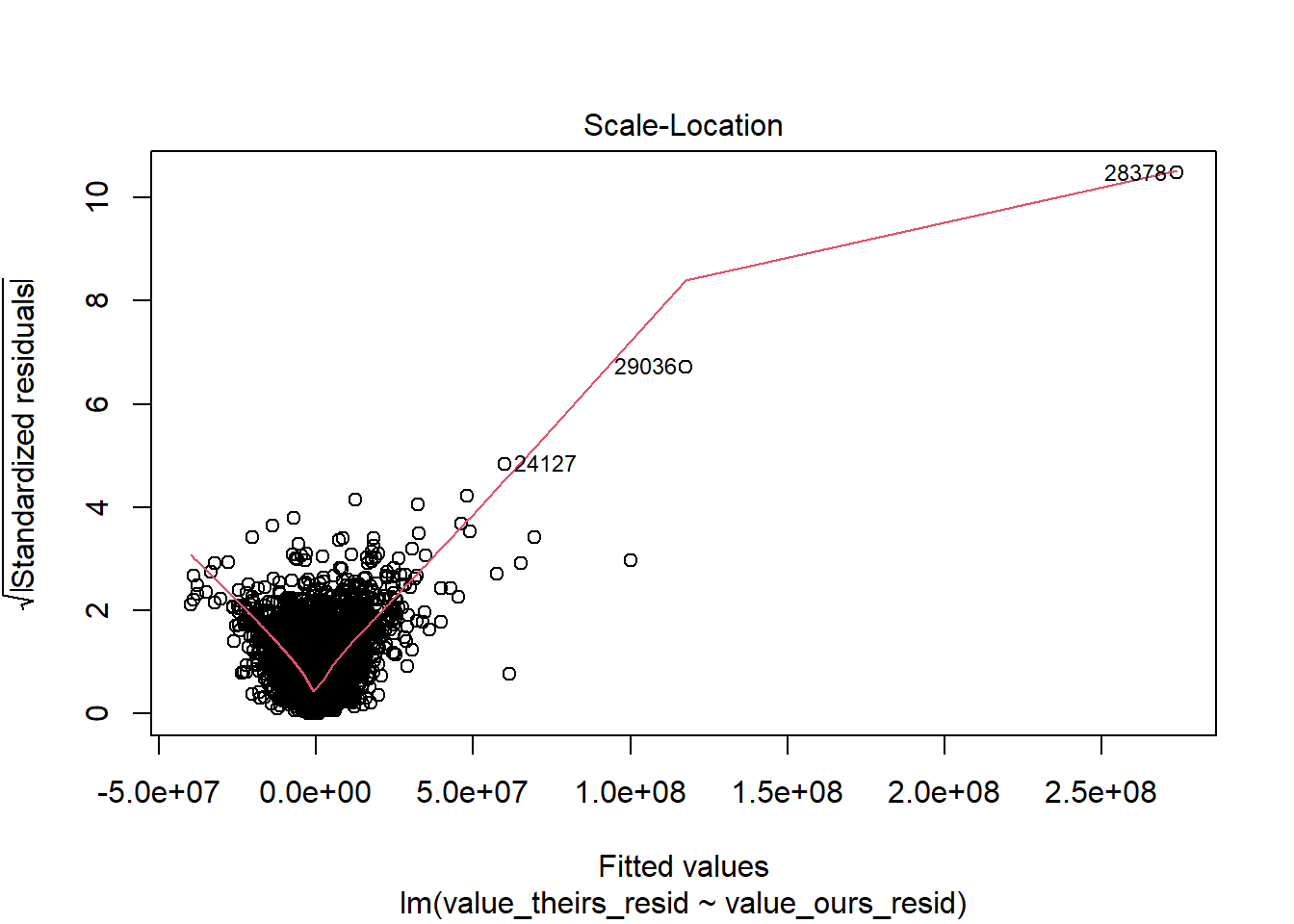
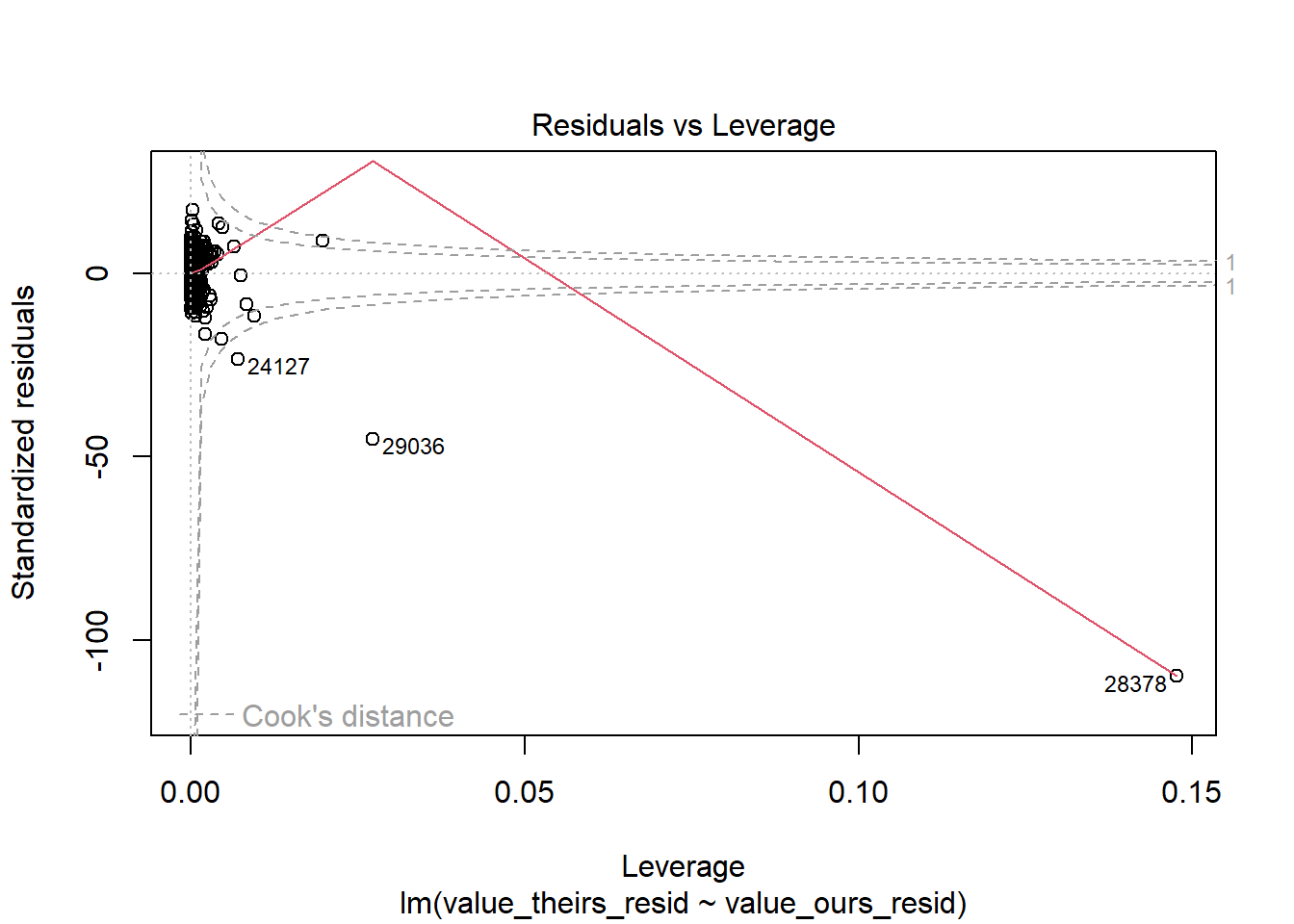
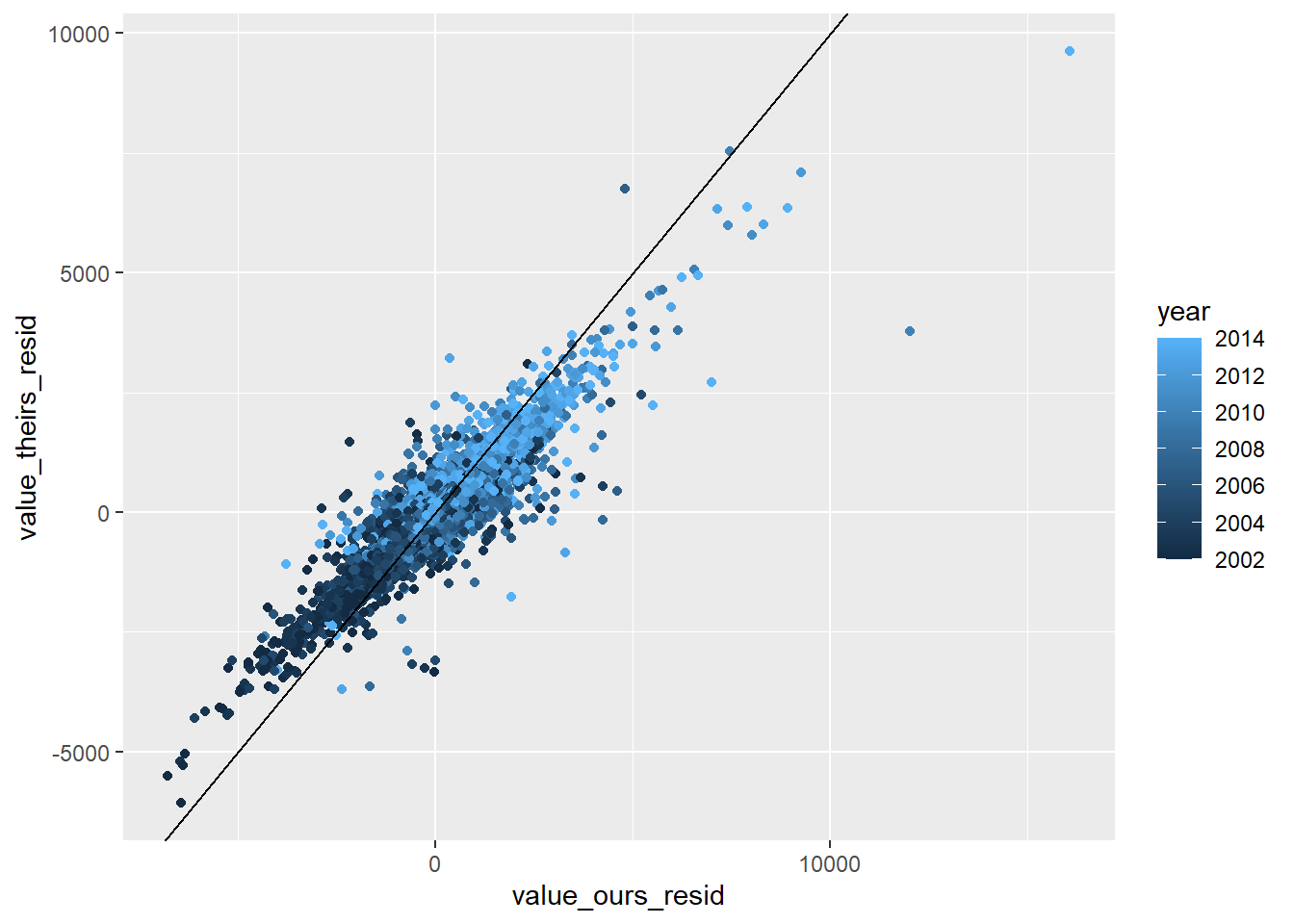
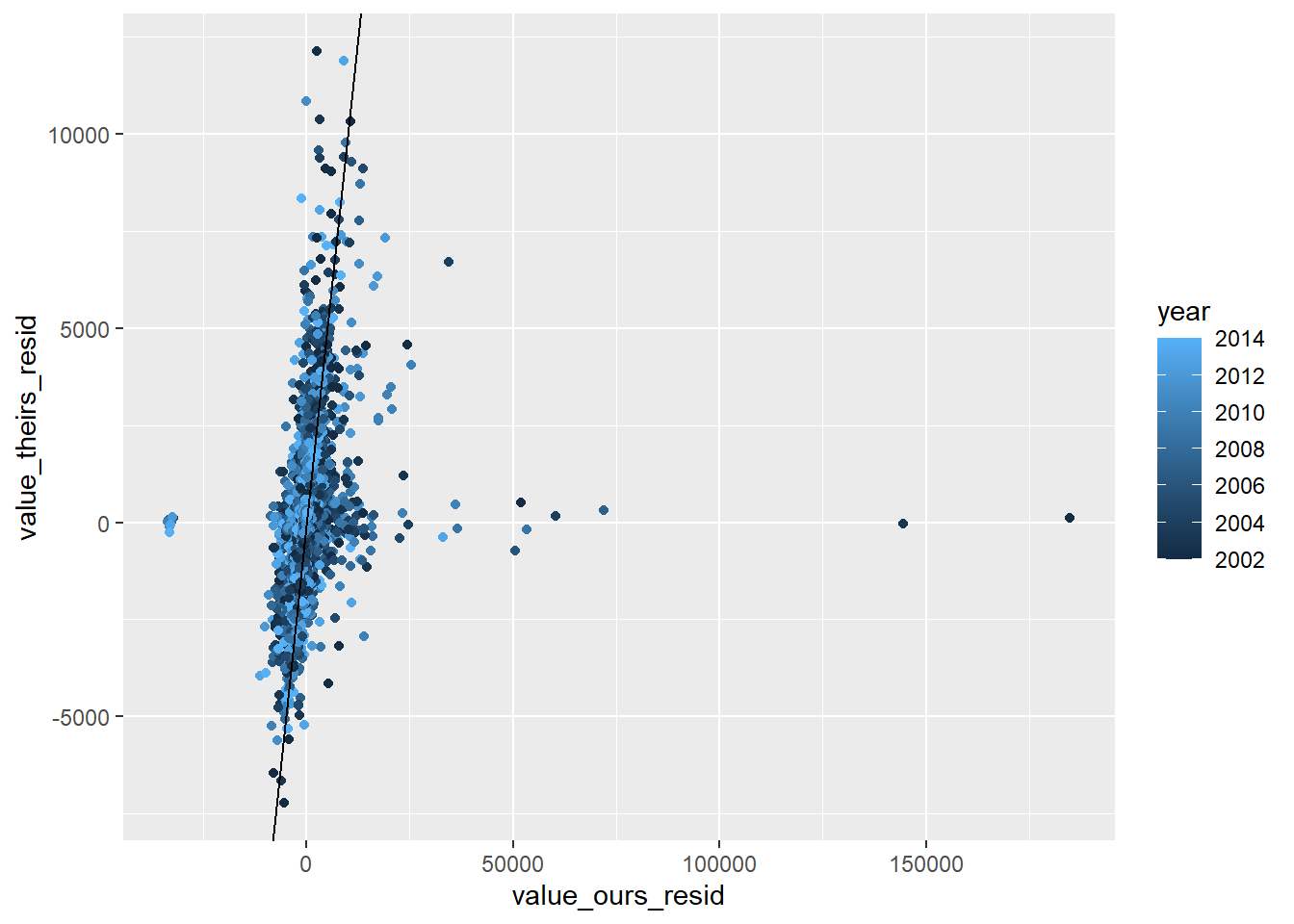
RAIS_joint_prit <- RAIS_joint %>% .[variable=="prit"] %>% .[!(is.na(value_ours)|is.na(value_theirs))]# estimate null model prit theirs to remove year + mun effectslm_prit_theirs <-summary(feols( value_theirs ~1| year + cod6, data = RAIS_joint_prit))lm_prit_ours <-summary(feols( value_ours ~1| year + cod6, data = RAIS_joint_prit))# get residulasRAIS_joint_prit$value_theirs_resid <- lm_prit_theirs$residualsRAIS_joint_prit$value_ours_resid <- lm_prit_ours$residualsRAIS_joint_prit %>%ggplot(aes(x=value_ours_resid, y = value_theirs_resid, color=year)) +geom_point() +geom_abline()
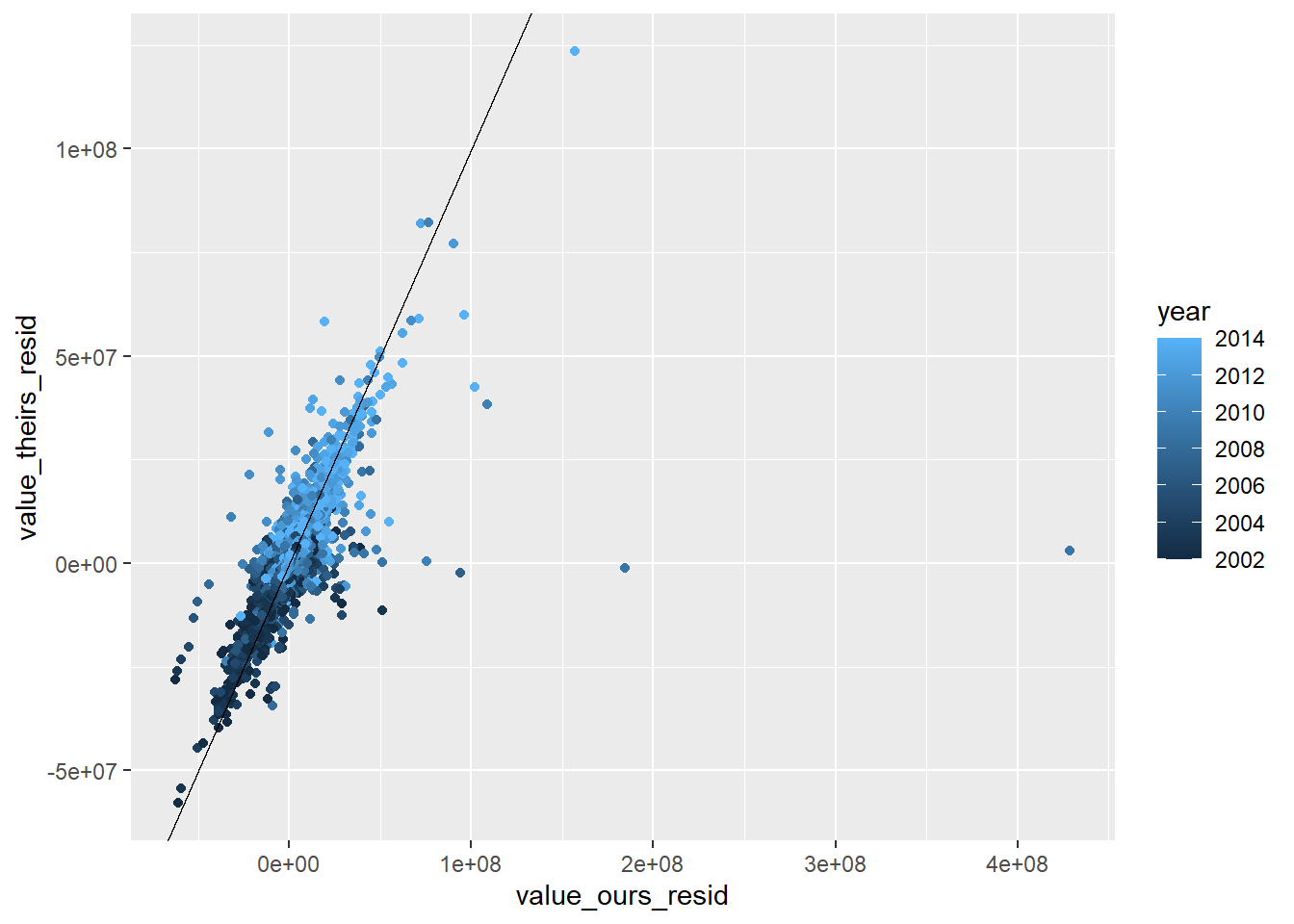
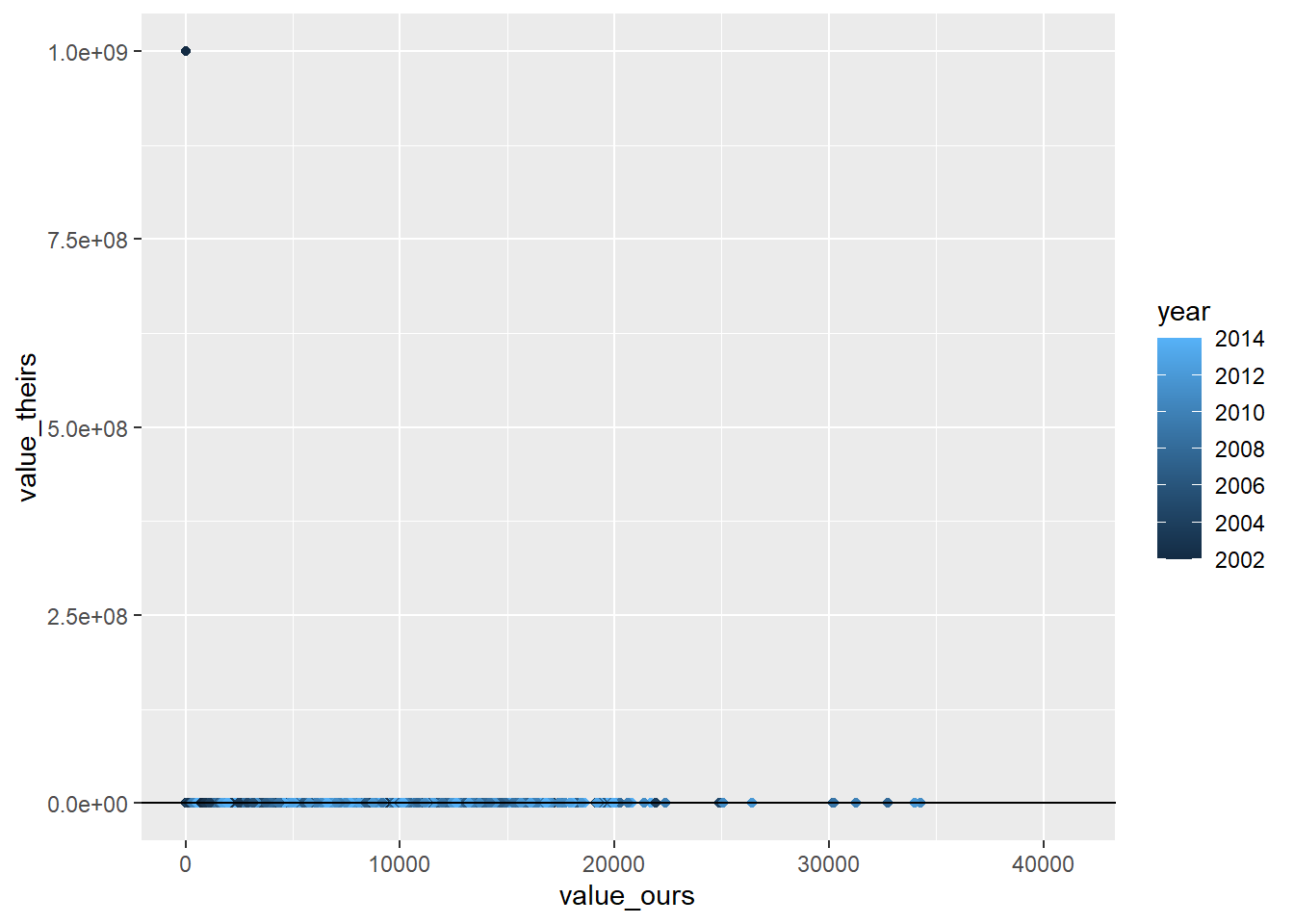
RAIS_joint_prin <- RAIS_joint %>%copy() %>%# already exclude the mega outlier .[variable=="prin"] %>% .[!(is.na(value_ours)|is.na(value_theirs))]# identify mega outliersmega_outlier <- RAIS_joint_prin %>% .[value_theirs>1000000] %>% .[, .(cod6, year)]RAIS_joint_prin <- RAIS_joint_prin[value_theirs<1000000]# estimate null model prin theirs to remove year + mun effectslm_prin_theirs <-summary(feols( value_theirs ~1| year + cod6, data = RAIS_joint_prin))lm_prin_ours <-summary(feols( value_ours ~1| year + cod6, data = RAIS_joint_prin))# get residulasRAIS_joint_prin$value_theirs_resid <- lm_prin_theirs$residualsRAIS_joint_prin$value_ours_resid <- lm_prin_ours$residualsRAIS_joint_prin %>%ggplot(aes(x=value_ours_resid, y = value_theirs_resid, color=year)) +geom_point() +geom_abline()
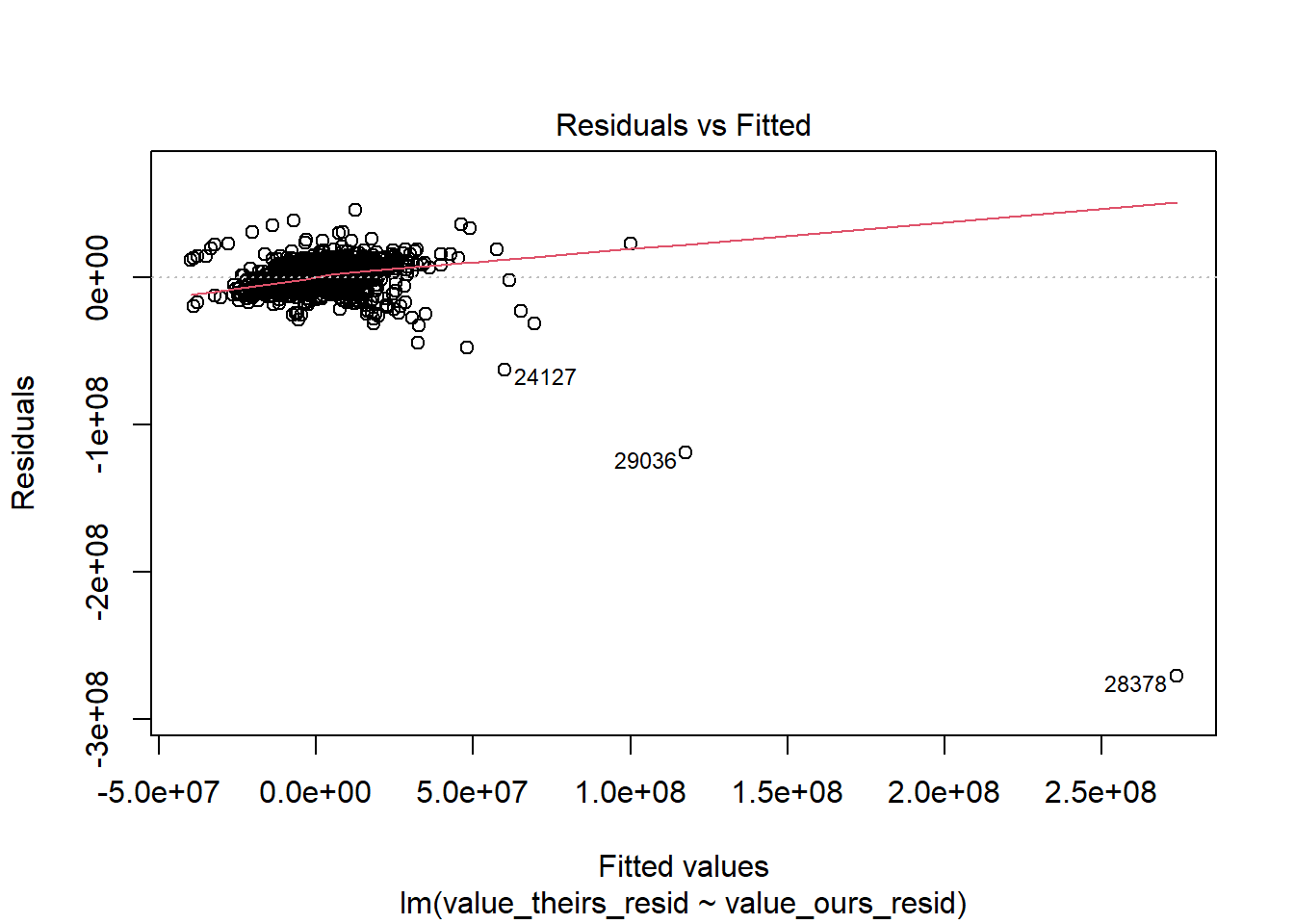
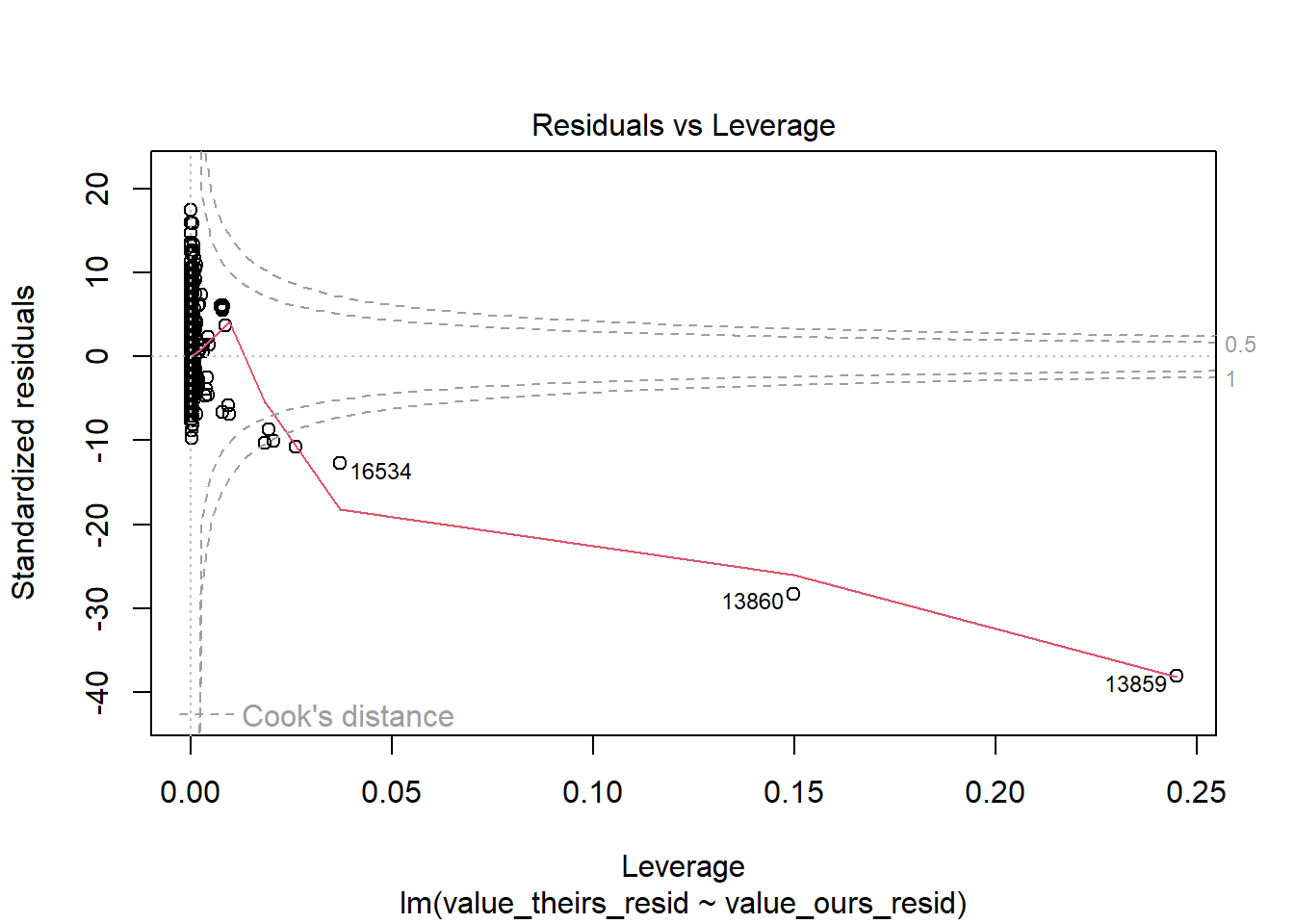
# the biggest issue are the top twohigh_leverage_prin <- RAIS_joint_prin %>% .[quantile(lm_leverage, .99) < lm_leverage] %>% .[order(-lm_leverage)] %>% .[1:2] %>% .[, .(year, cod6)]merge(RAIS_joint_prin, high_leverage_prin, by =c("cod6", "year"), all=F) %>% .[order(-lm_leverage)]
High leverage Total Earnings
Code
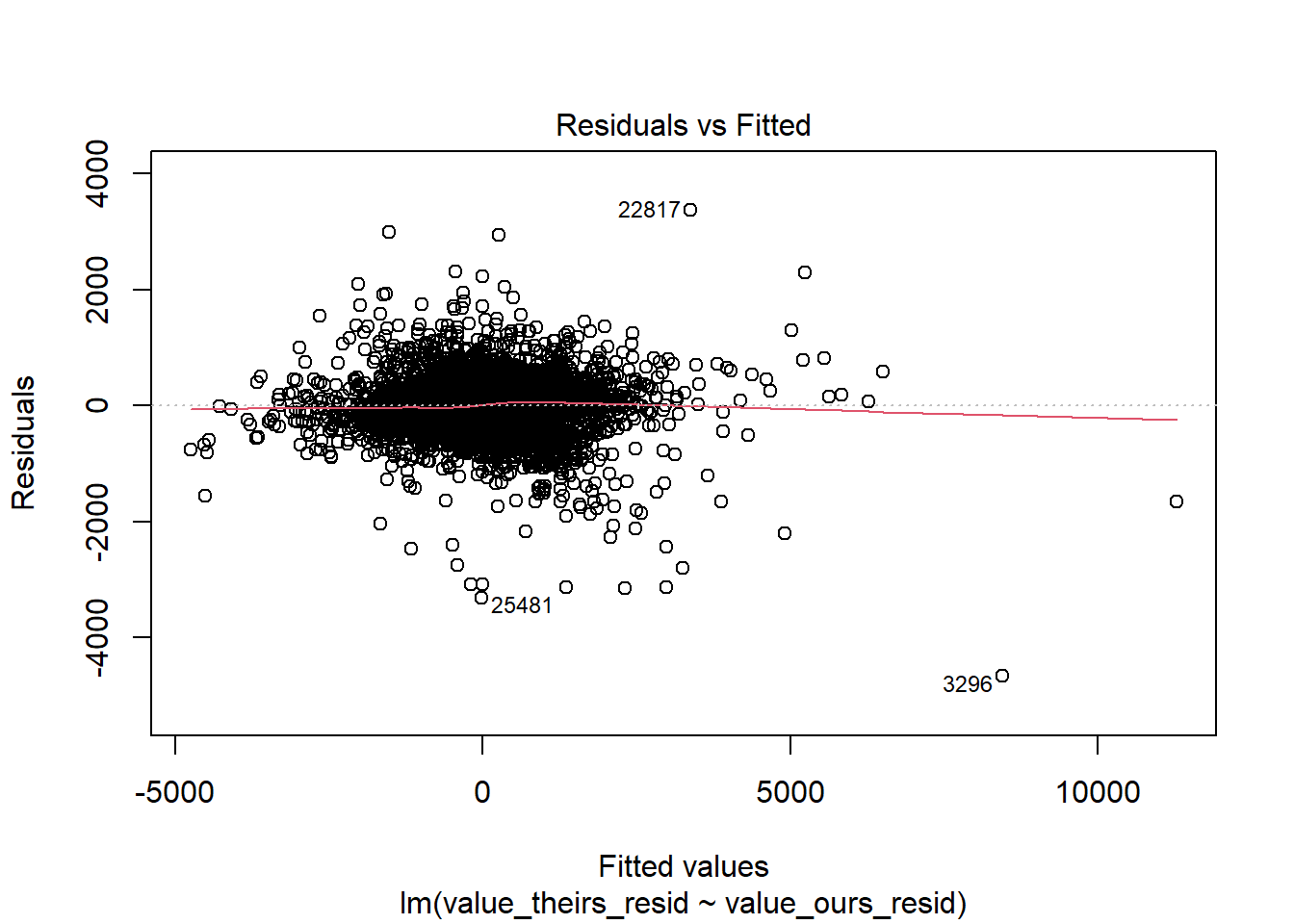
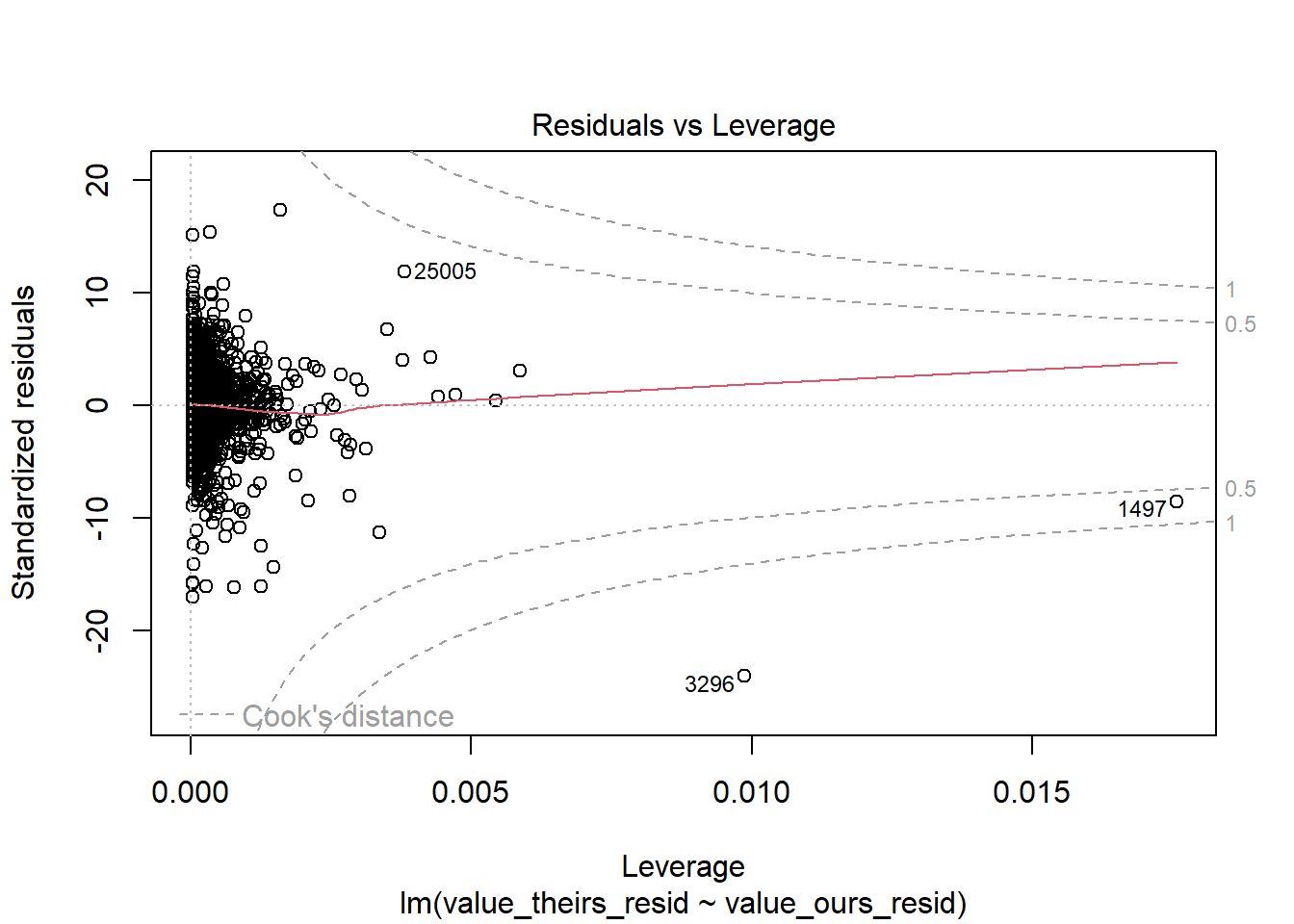
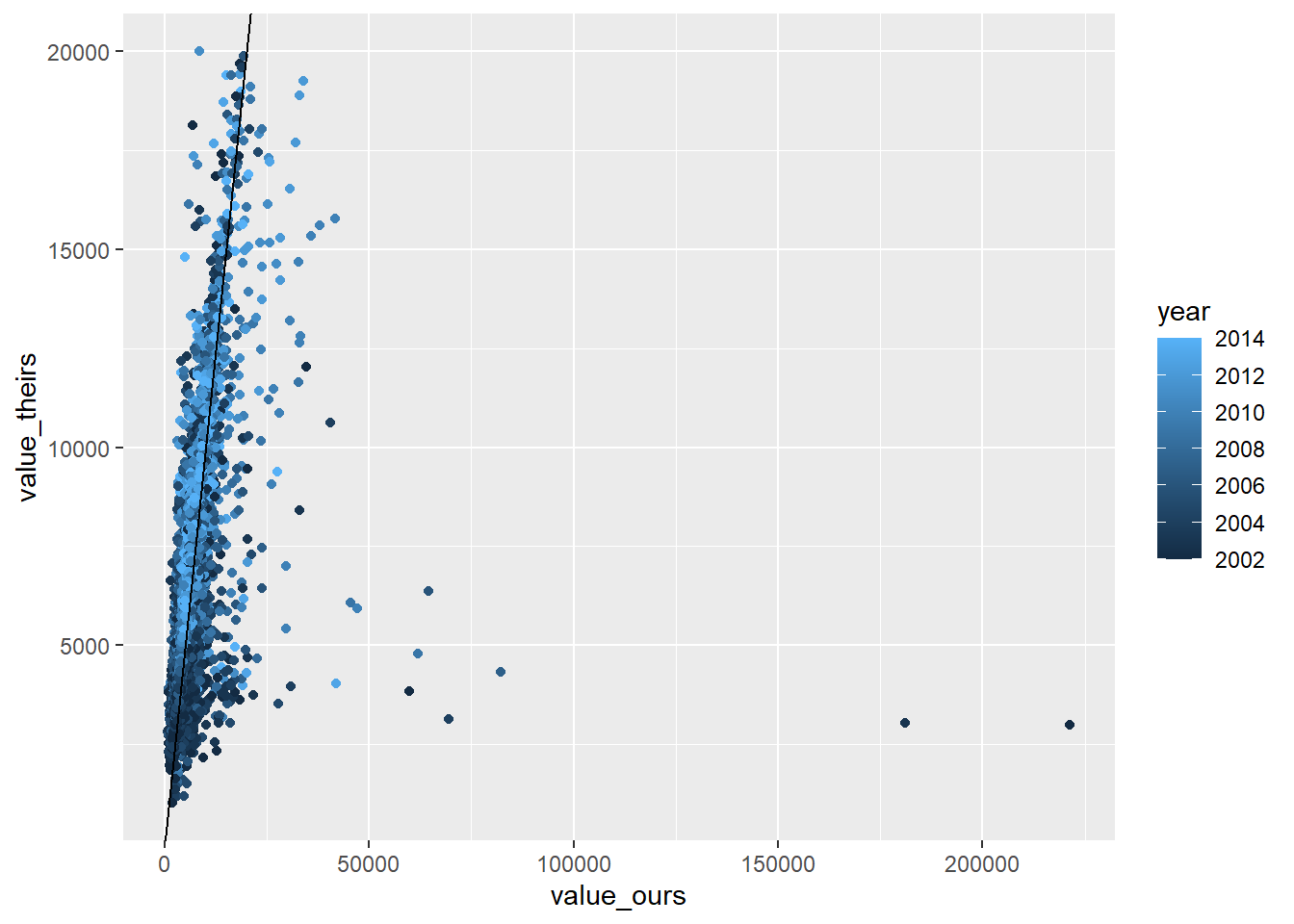
RAIS_joint_priw <- RAIS_joint %>%copy() %>%# already exclude the mega outlier .[variable=="priw"] %>% .[!(is.na(value_ours)|is.na(value_theirs))]# estimate null model priw theirs to remove year + mun effectslm_priw_theirs <-summary(feols( value_theirs ~1| year + cod6, data = RAIS_joint_priw))lm_priw_ours <-summary(feols( value_ours ~1| year + cod6, data = RAIS_joint_priw))# get residulasRAIS_joint_priw$value_theirs_resid <- lm_priw_theirs$residualsRAIS_joint_priw$value_ours_resid <- lm_priw_ours$residualsRAIS_joint_priw %>%ggplot(aes(x=value_ours_resid, y = value_theirs_resid, color=year)) +geom_point() +geom_abline()
# the biggest issue are the top fourhigh_leverage_priw <- RAIS_joint_priw %>% .[quantile(lm_leverage, .99) < lm_leverage] %>% .[order(-lm_leverage)] %>% .[1:4] %>% .[, .(year, cod6)]merge(RAIS_joint_priw, high_leverage_priw, by =c("cod6", "year"), all=F) %>% .[order(-lm_leverage)]
High leverage Total Earnings
Code
# compile list of observations to removeremove_these <-rbind(high_leverage_prin, high_leverage_prit) %>%rbind(., high_leverage_priw) # create stata code to removeremove_these %>% .[, paste("drop if year == ", year, " & cod6 == ", cod6, " ")]
[1] "drop if year == 2014 & cod6 == 150215 \n "
[2] "drop if year == 2010 & cod6 == 210405 \n "
[3] "drop if year == 2009 & cod6 == 411580 \n "
[4] "drop if year == 2009 & cod6 == 412350 \n "
[5] "drop if year == 2014 & cod6 == 150215 \n "
[6] "drop if year == 2002 & cod6 == 291180 \n "
[7] "drop if year == 2003 & cod6 == 291180 \n "
[8] "drop if year == 2007 & cod6 == 293305 \n "
[9] "drop if year == 2004 & cod6 == 150570 \n "
Code
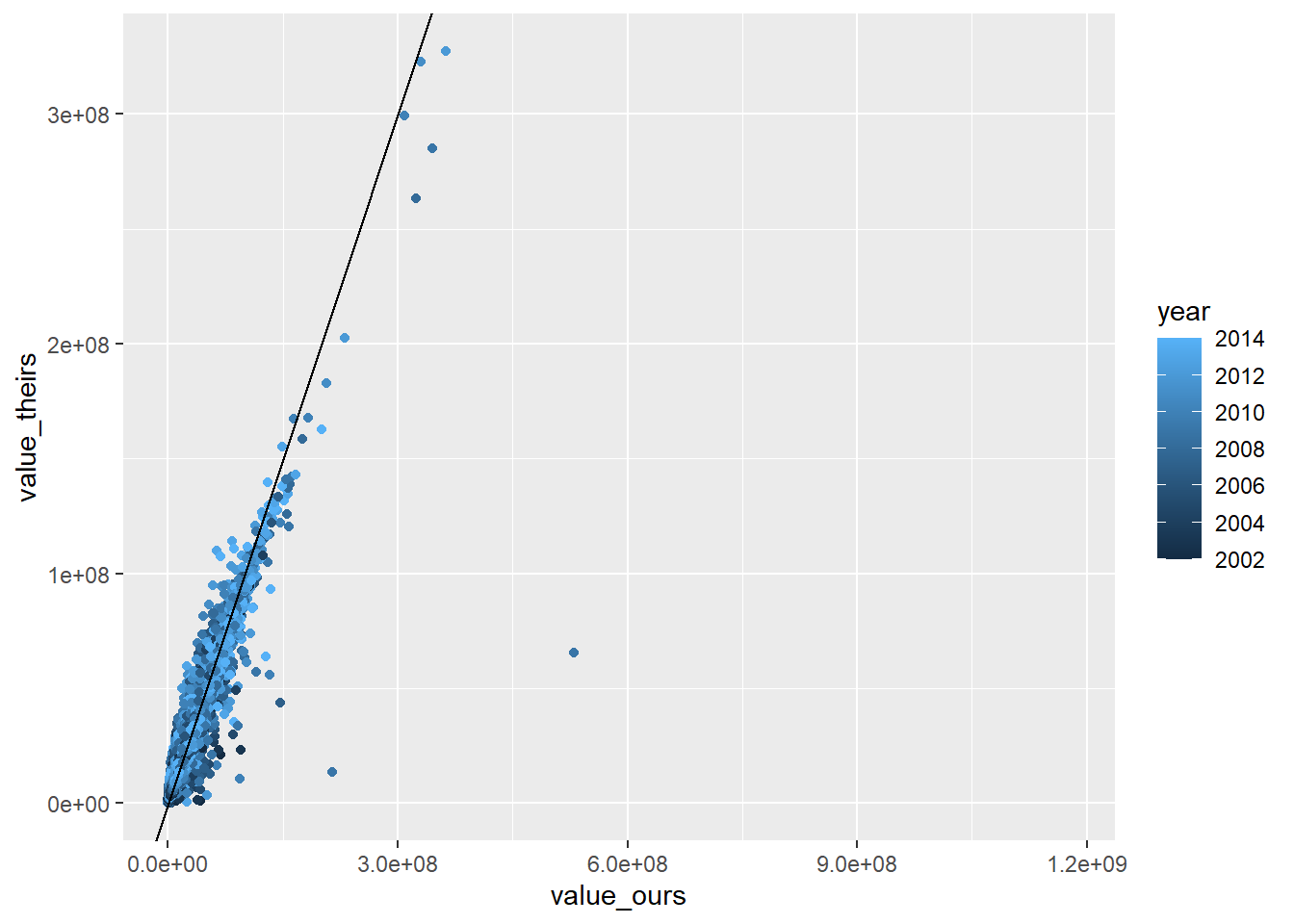
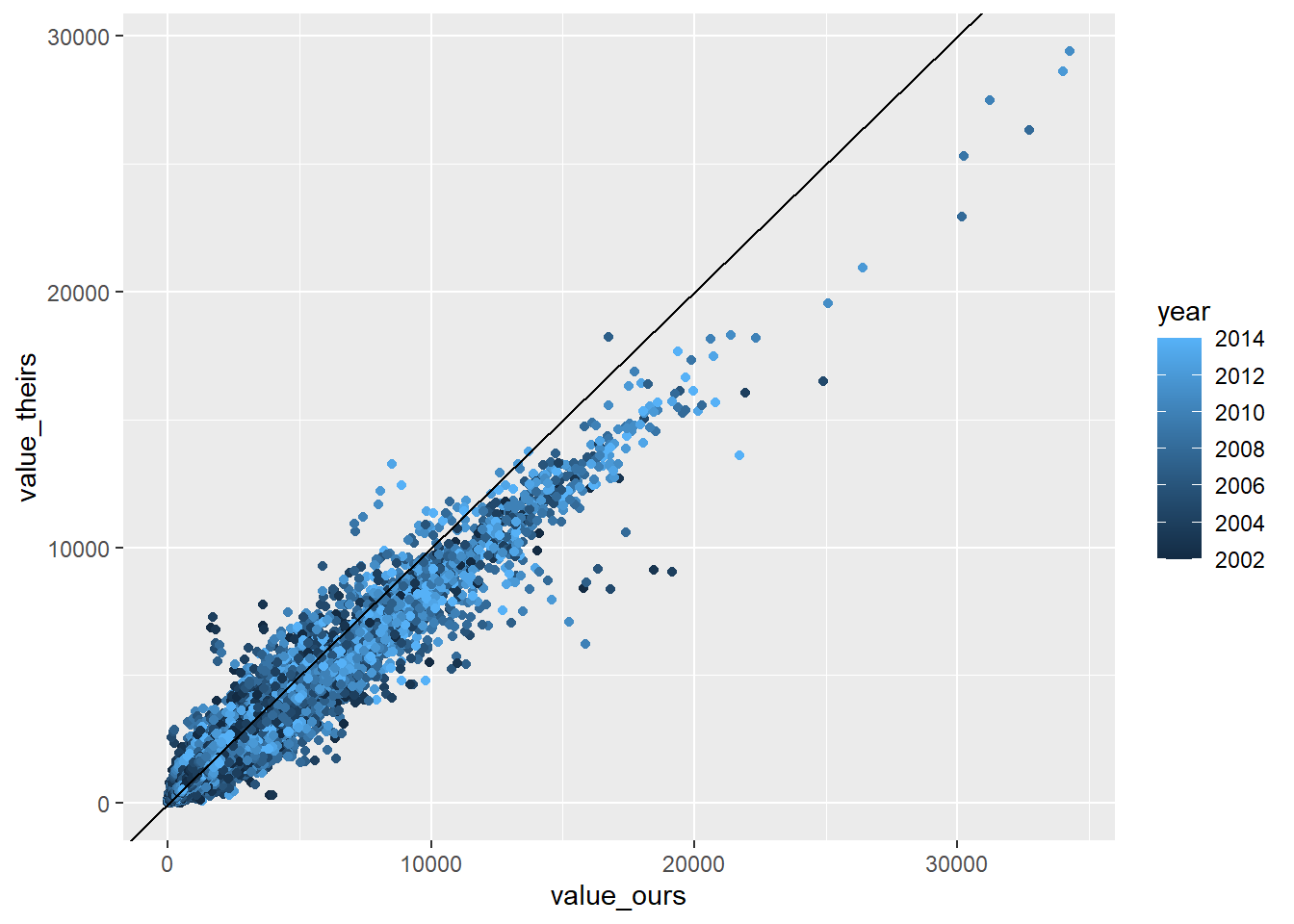
RAIS_joint %>% .[variable=="prin"] %>%ggplot(aes(x=value_ours, y = value_theirs, color=year)) +geom_point() +geom_abline()