In this page, we look at differences in the output data-sets which create Their vs Our figures and tables. We begin with the author’s and our estimation data-sets and progressively test hypotheses which may shed light into differences between our results.
The table 7 reduced-form estimates from Corbi, Papaioannou, and Surico (2018) comes from regressions similar to this one from column (1): reghdfe var lfpmhat B8XX, a(i.cod6 i.cutoffy i.siglay) cl(micro) (see Section 7.1.1 for details). In Section 7.2 we investigate differences across the output FPM variables. In Section 7.3 we alter final estimation data-sets determine what variables and restrictions may or may not impact the final estimates, in order to uncover the ultimate cause of the differences in the samples.
There are many different conclusions that may come from these analyses, though none definitively point to one cause for differences in estimates and significance. The 4% bandwidth estimates for Private Earnings and Employment yield the most significant results, generally. Small changes in bandwidth may be important towards getting significant results. Their labor market statistics seem to play a more important role than other factors. I.e. When we compare the inclusion of just their FPM, just their LM statistics and the combination of the two, their LM seem to contribute the most.
7.1.1 Regression details
Explaining the above regression model. var is a log labor market variable. lfpmhat is the theoretical FPM computed in the dofile. B8XX is a cheeky variable coded as 1 for observations in the 2% or 4% relative bandwidths and missing otherwise; it is responsible for excluding obsevations form each individual estimation. cod6, cutoffy and siglay are municipality, relative bandwidth-year and state-year fixed effects. micro stands for micro-regions.
7.2 Differences across FPMs in the final data-sets
In this section, we load Their and Our output data-sets. These are the data-sets which are used to create the figures and images. In this section, we ONLY look at municipality-years shared amongst both data-sets.
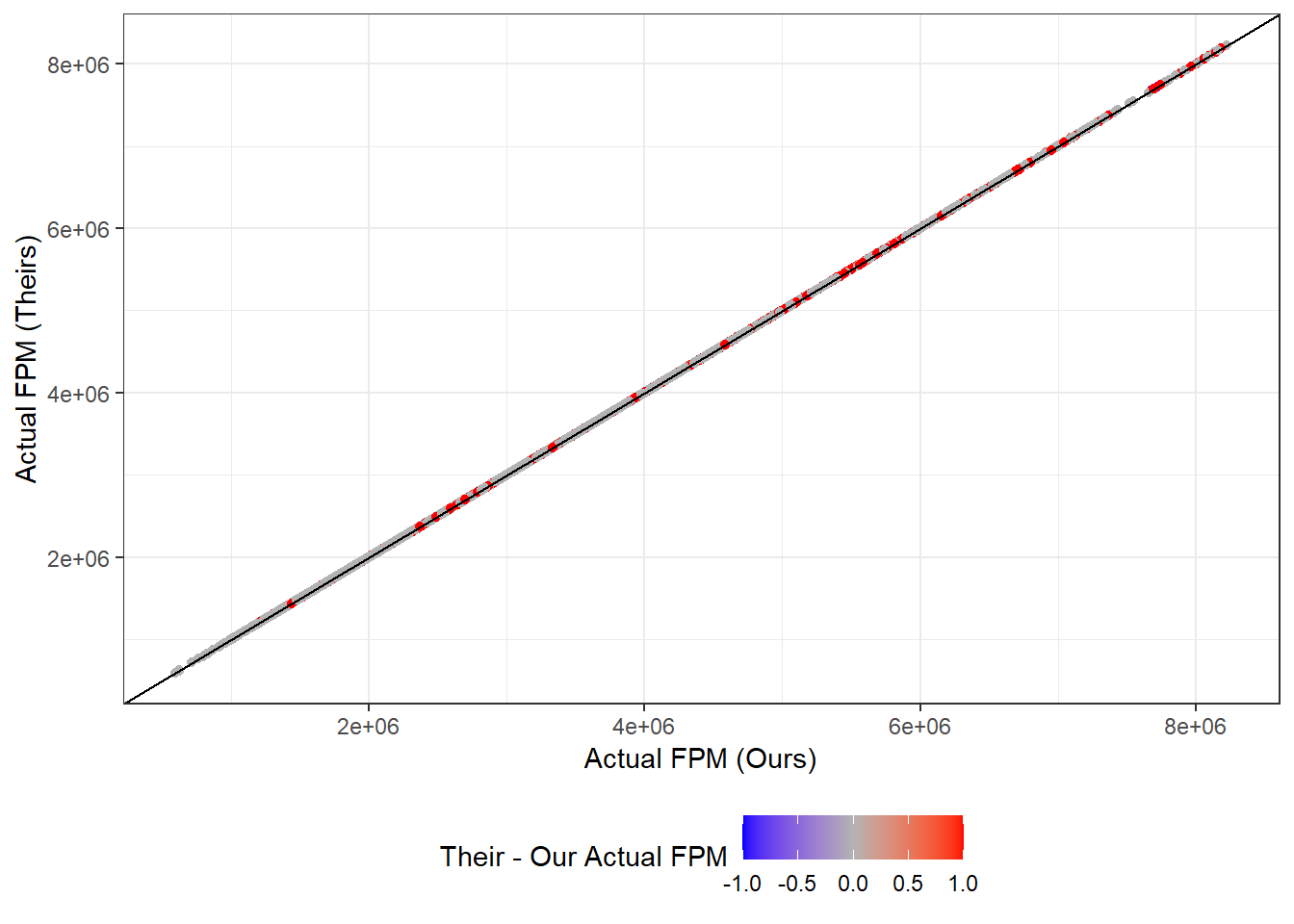
Figure 7.1 illustrates that FPM is pretty much equal across Their and Our output data-sets, with minor differences being attributed to rounding errors. The two municipality-years where input FPMs were off by more than 1000BRL are (apparently) dropped in the cleaning do files.
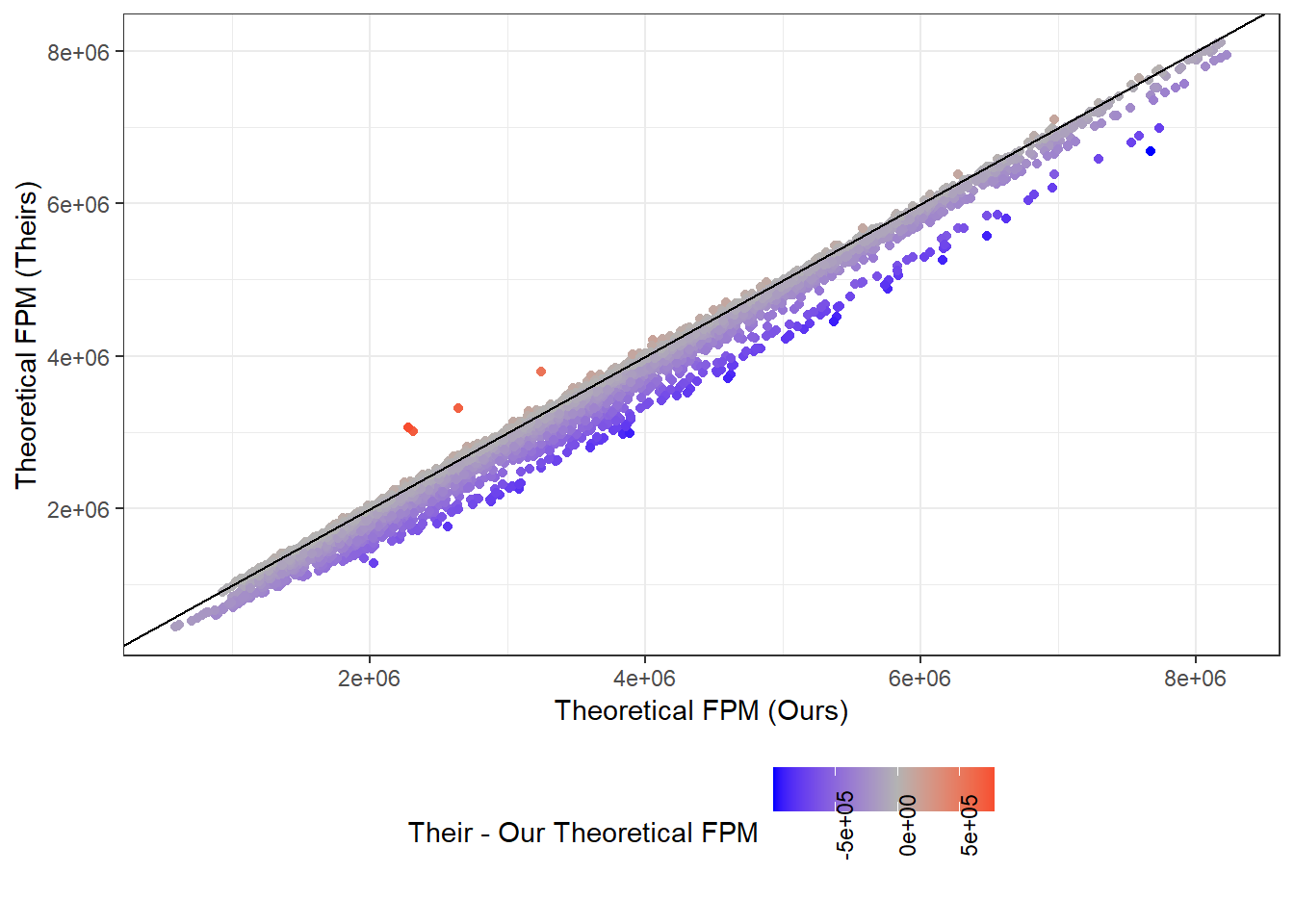
Figure 7.2 illustrates that the Theoretical FPM (AKA \(\hat{FPM}\)), (computed within the cleaning code) remains quite different across samples, despite being strongly positively correlated. Table 7.1 highlights this relationship by regressing one on the other and controlling for special cases; which itself has a significant association with the theoretical transfers when controlling for our theoretical FPMs. These differences across samples may come from a range of different sources. To compute \(\hat{FPM}\), we require data on: 1) all FPM transfers for all municipalities for each year and 2) the share each municipality ought to receive from the total national FPM budget. (See other pages for further information.)
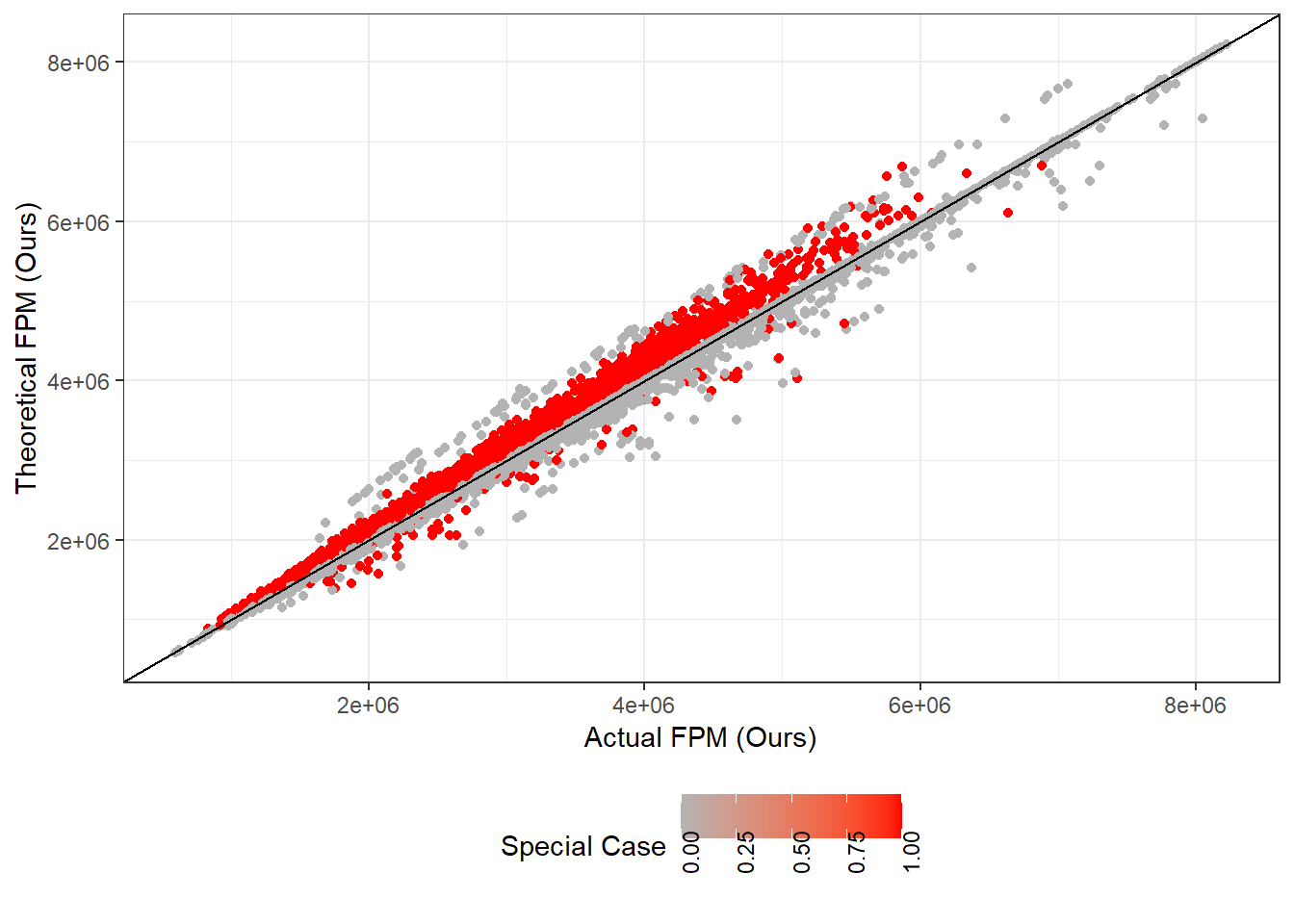
Figure 7.3 depicts the relationship between the actual and theoretical FPM transfers in our data-set. It, along with Table 7.2, highlight that the relationship is positive but by no means is it a perfect fit. We notice that municipalities labelled as special cases have statistically significantly higher theoretical transfers, on average, than in reality.
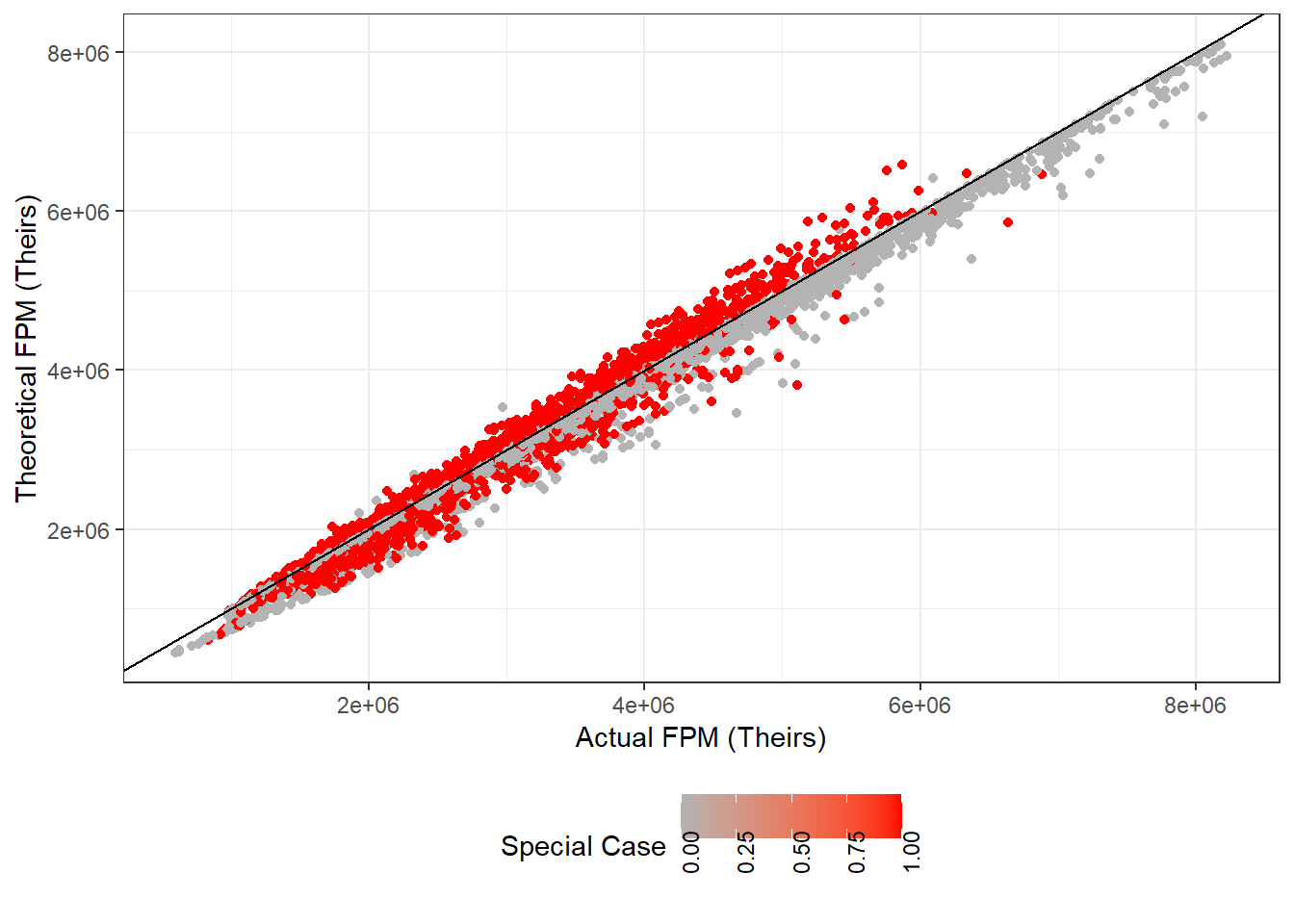
The same is true in their data-set. Figure 7.4 and Table 7.3 are analogous to Figure 7.3 and Table 7.2. The one difference is that Their special cases are have a lower average theoretical FPM than Ours. This could be an artifact of Their mishandling of special cases though; there exists a large number of missing values for their 1997 coefficients for municipality-years that ought to be granted special treatment.
Table 7.3: Theoretical FPM ~ Actual FPM + 1[Special Case]
Characteristic
Beta
p-value
(Intercept)
-39,665
<0.001
Actual FPM (Theirs)
0.99
<0.001
Special Case
68,538
<0.001
R²
0.995
Adjusted R²
0.995
Sigma
92,123
Statistic
3,750,108
p-value
<0.001
df
2
Residual df
36,166
No. Obs.
36,169
7.2.1 Are these differences in \(\hat{FPM}\) what drive the differences in estimates?
Probably not. In order to answer this question, we only consider municipality-years common to both data-sets and substitute our Theoretical FPM with theirs. Unfortunately, we are not able to replicate their estimates. Despite not being perfectly correlated, both variables are still highly correlated. Therefore, it shouldn’t come as a surprise that substituting one for the other would make our estimates postive and significant. In any case, we cannot rule out that differences in the computation of the Theoretical FPM may play a role
7.3 Evaluating table 7 with many versions of the data-sets
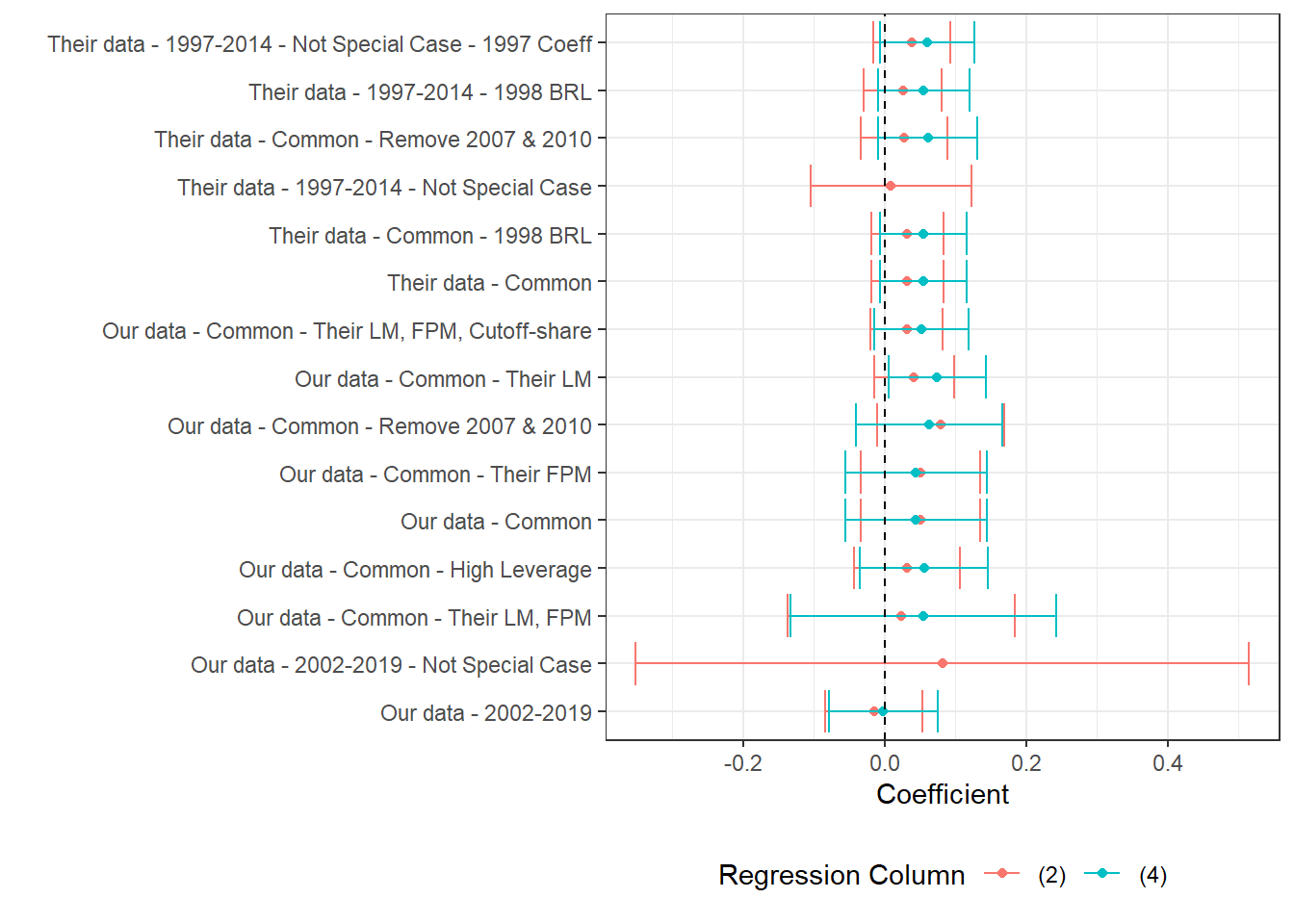
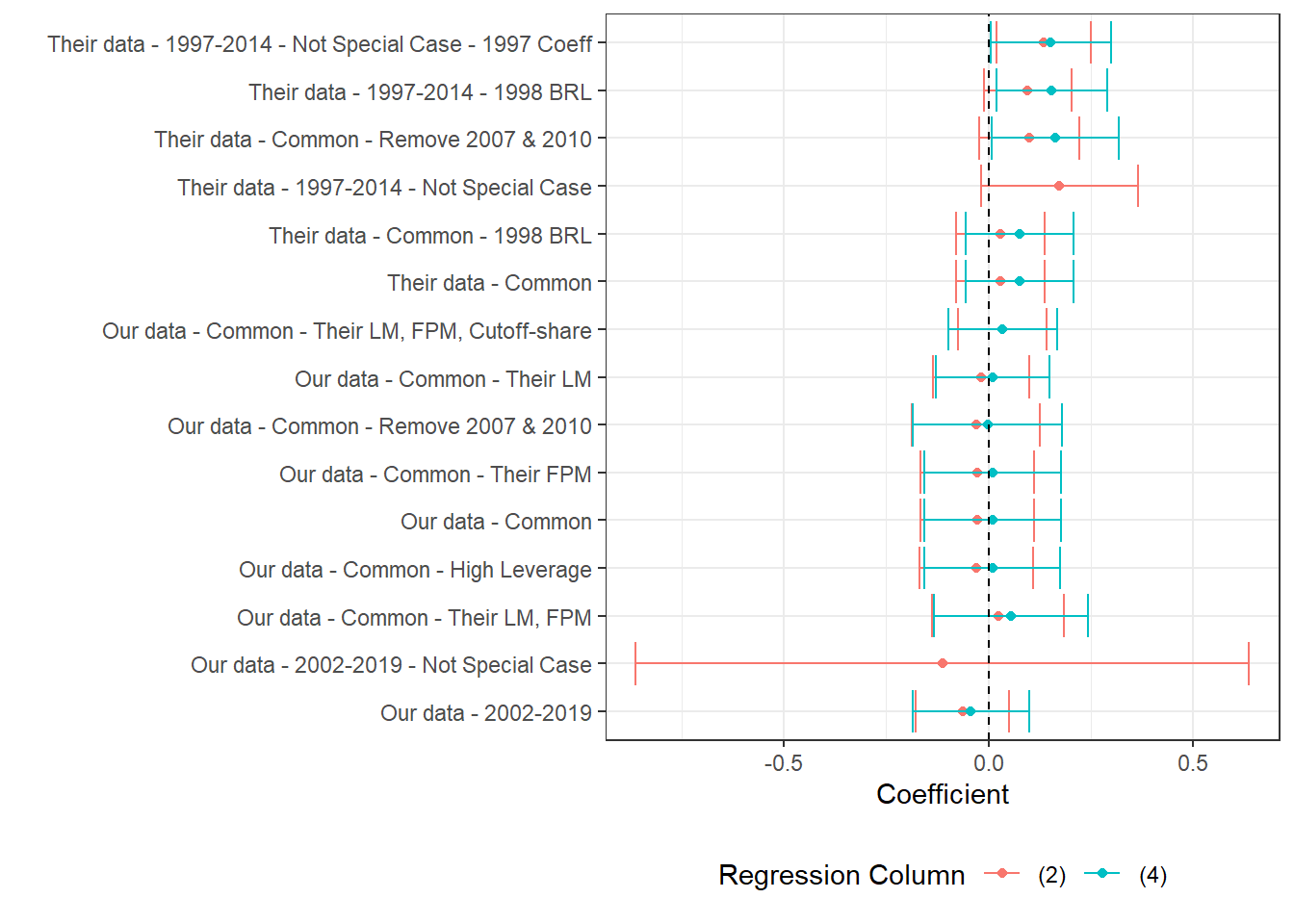
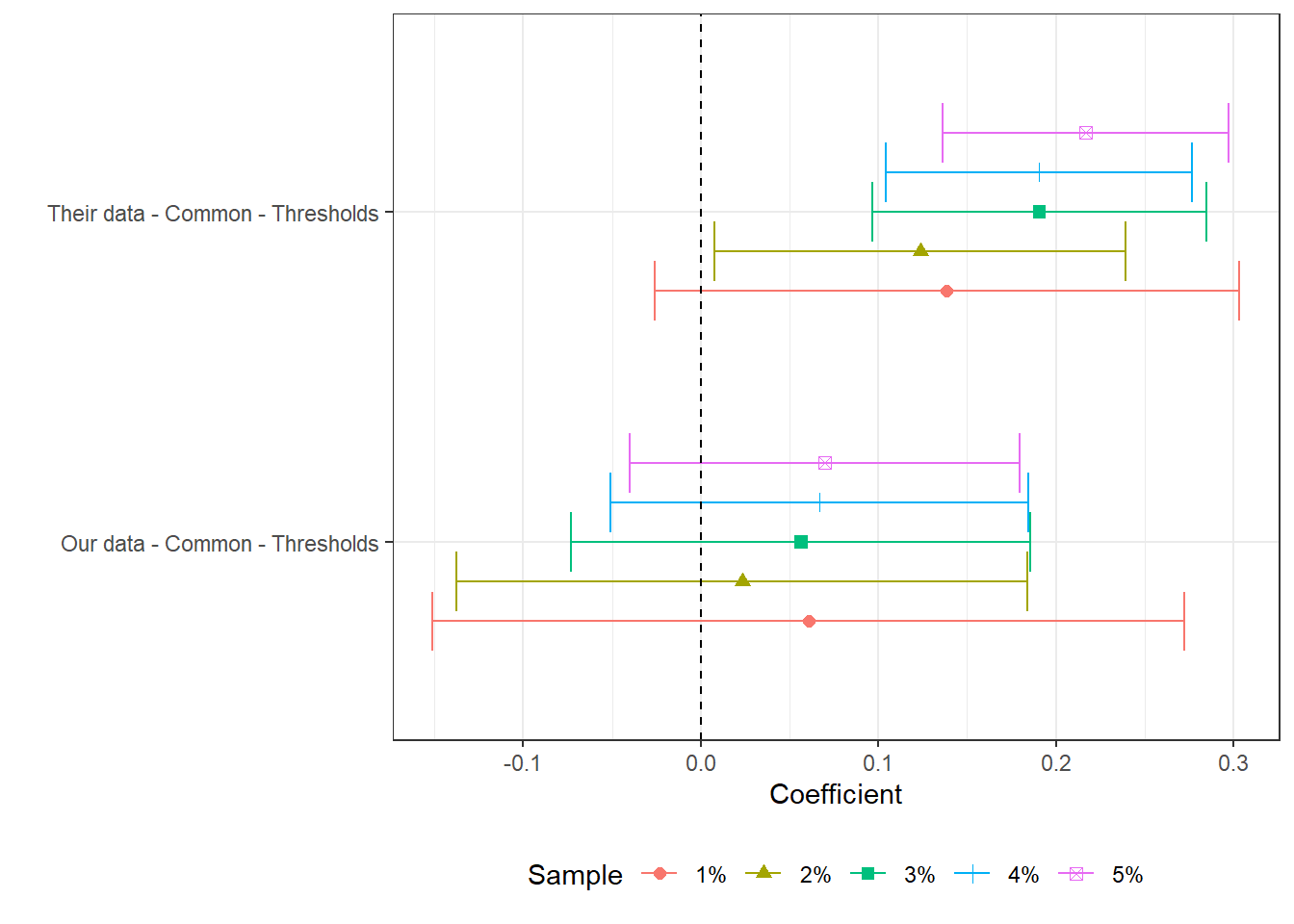
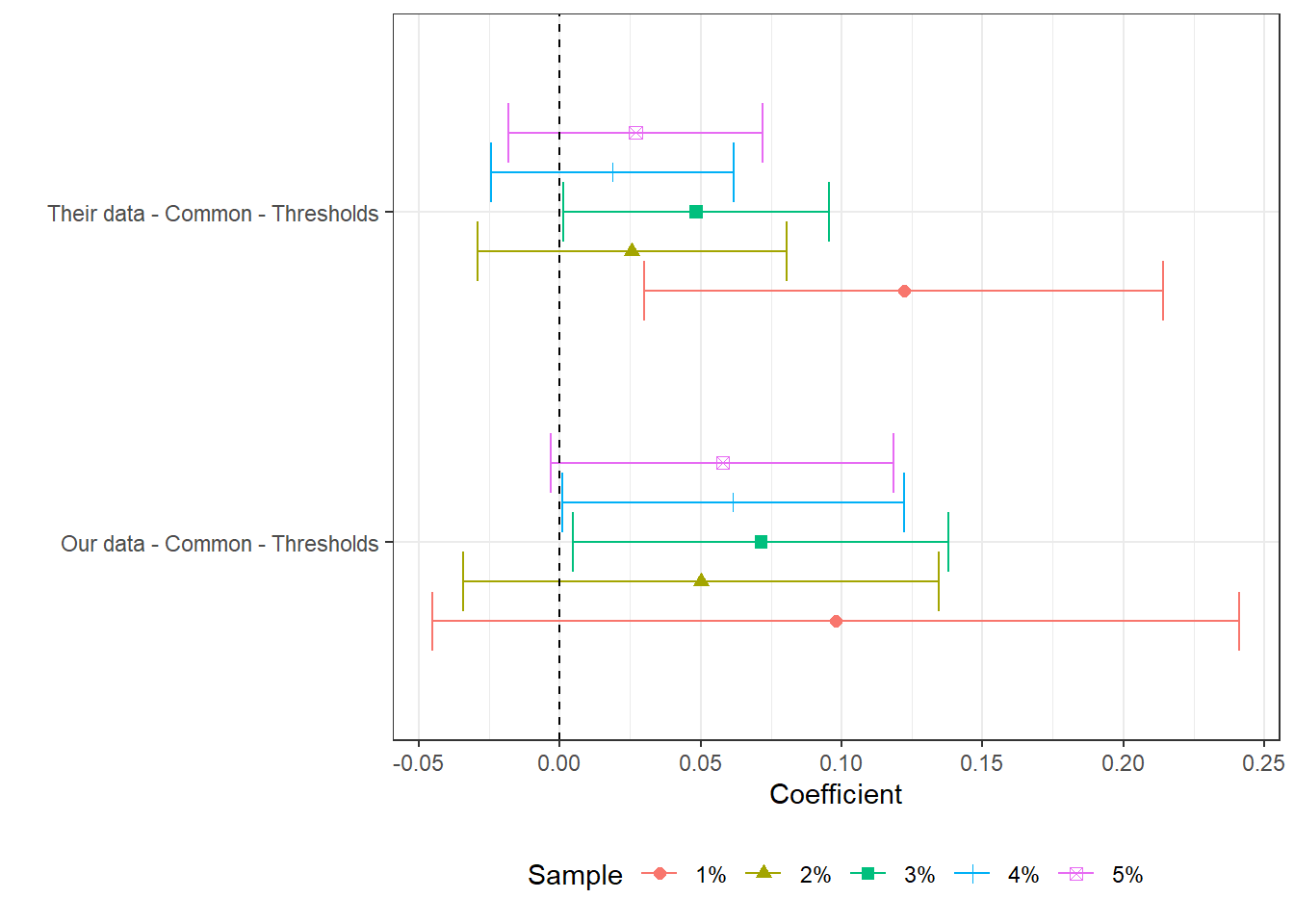
In this section we test a number of hypotheses to try to uncover the main reason why, despite having very similar inputs, Our estimates are not significant while Their estimates are. Given the large number of individual estimations, we present the data in three parts. First, we look at estimations for the 4% and 2% relative bandwidths independently. These are available in Section 7.3.2 and Section 7.3.3. In section Section 7.3.4 we then present estimates for regressions using 1%, 2%, 3%, 4% and 5% relative bandwidths, comparing Our and Their estimation samples for the municipality-years common to both data-sets.
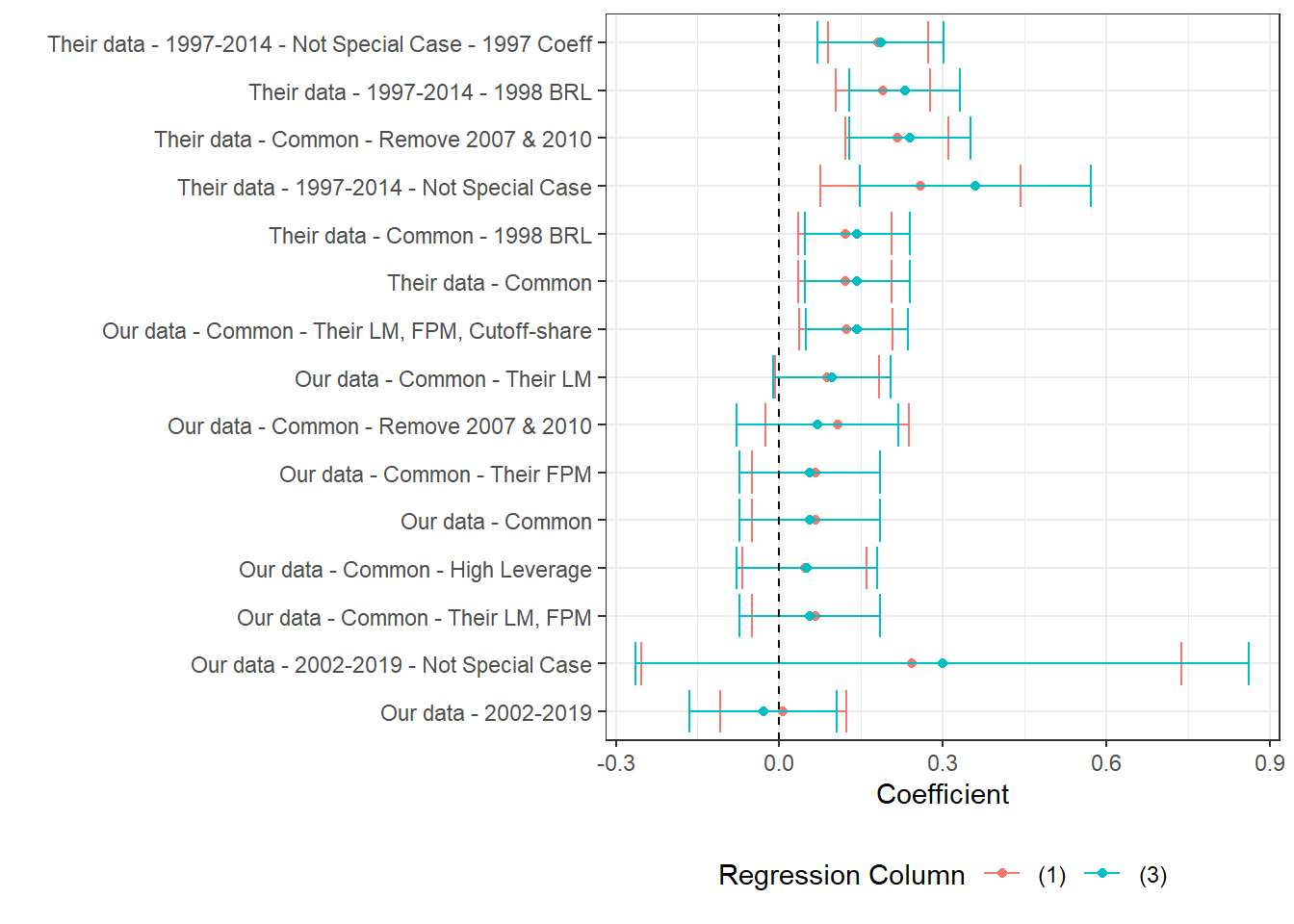
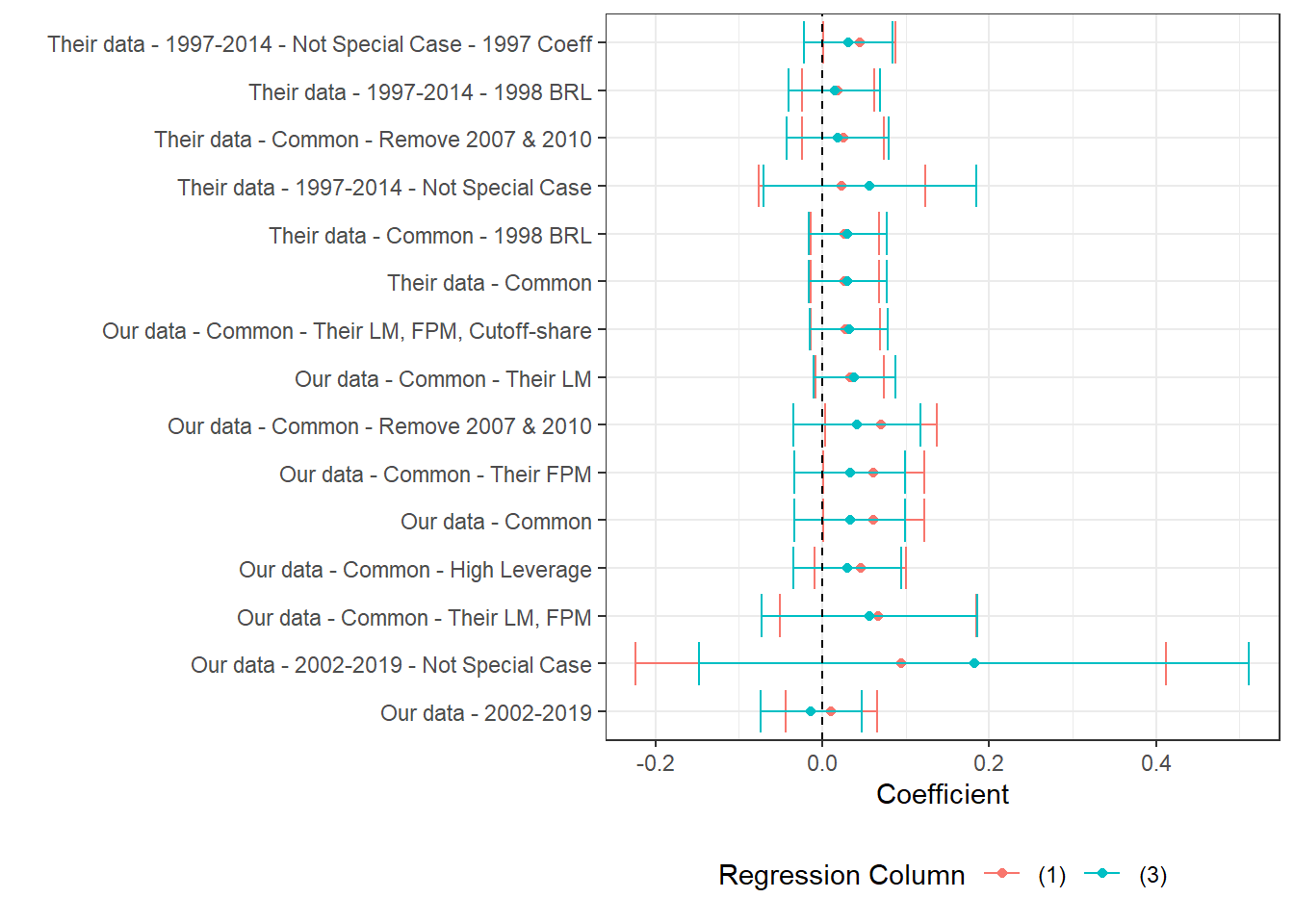
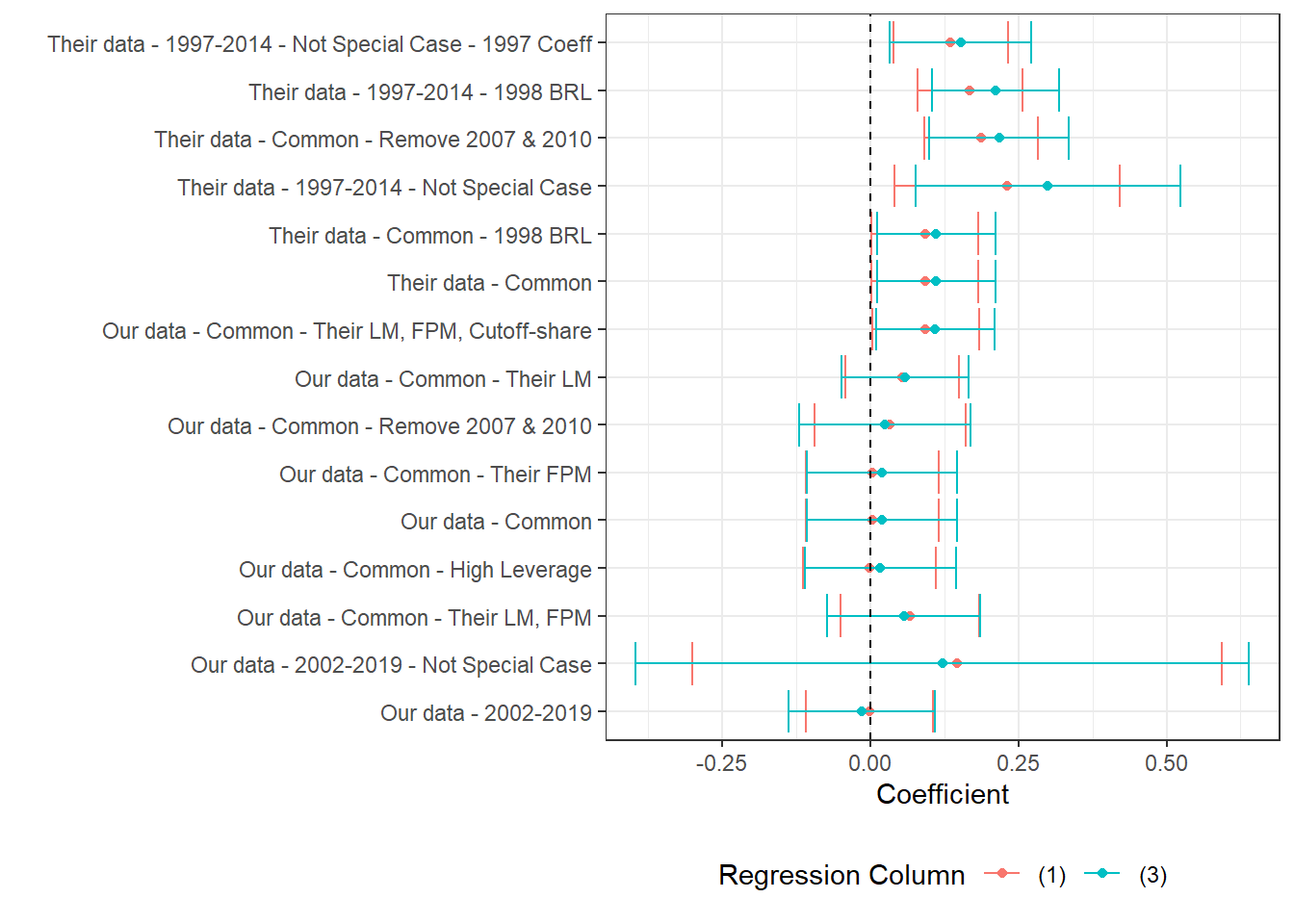
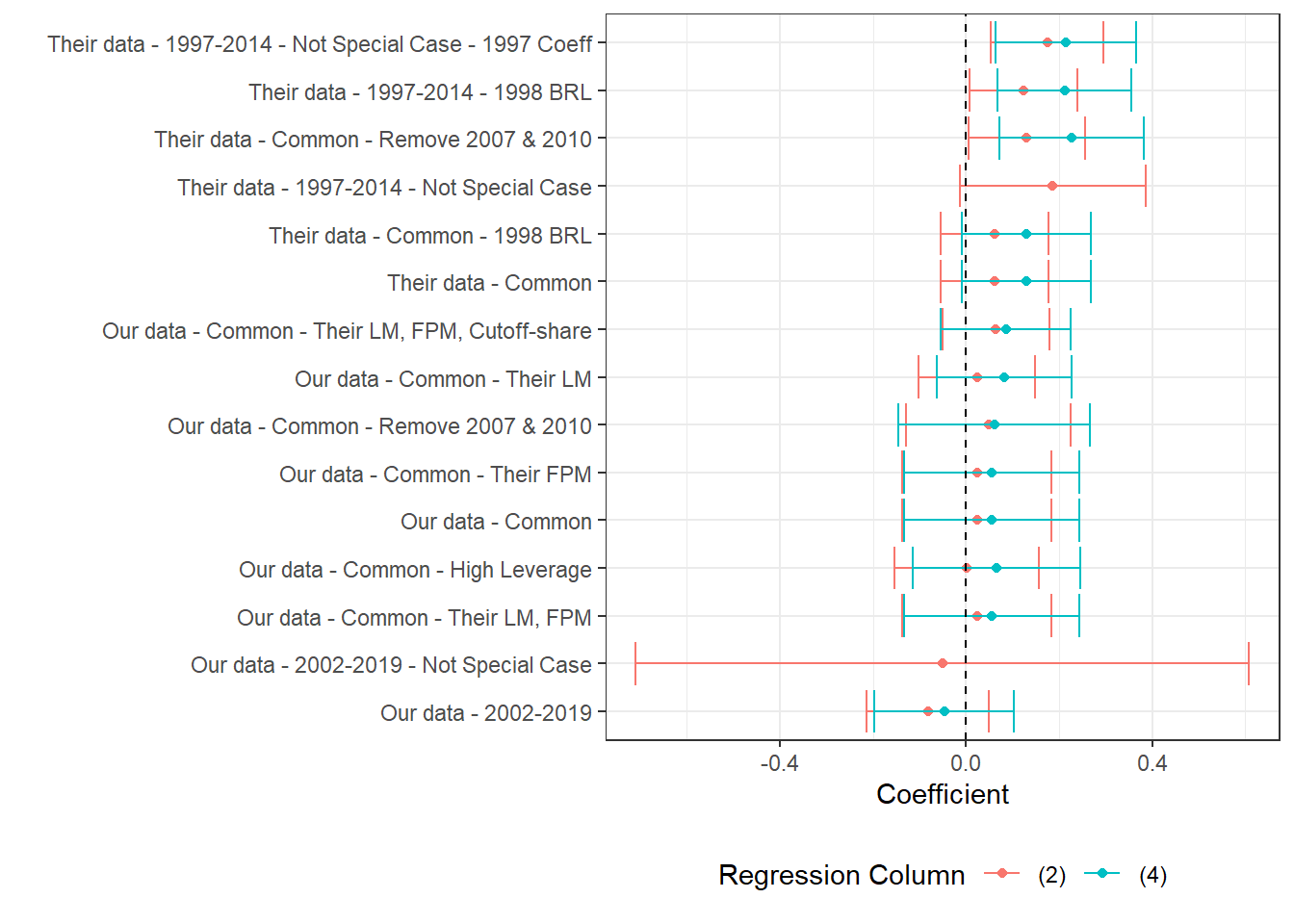
Section 7.3.2 and Section 7.3.3 contain three figures each. Each of the three figures in each section corresponds to one labor market outcome: Log Private Earnings (prit), Log Private Wages (priw) and Log Private Employment (prin). Each figure presents the point estimate and 95% confidence interval of the regression specified in the y-axis. Two coefficients are shown per regression, one controlling for first-order polynomials (3,4) and the other not (1,2).
See Table 7.4 for explanations of each regression. All regressions are performed in Stata and are available under 3_our_tab7_replication.do. The regression output is converted to .xlsx format then cleaned in R.
This set of regressions use our replication data for the full 2002-2019 sample. All estimates are in 2000BRL.
Our data - 2002-2019 - Not Special Case
This set of regressions use our replication data for the full 2002-2019 sample. All estimates are in 2000BRL. We run the regressions excluding special municipalities prior to 2008.
Our data - Common
This set of regressions use our replication data with municipality-years present in both data-sets. All estimates are in 2000BRL.
Our data - Common - High Leverage
This set of regressions use our replication data with municipality-years present in both data-sets. Additionally, we remove observations whose labor market statistics are outliers when compared across samples. We regress their LM variables on ours and remove variables with significant leverage. All estimates are in 2000BRL.
Our data - Common - Remove 2007 & 2010
This set of regressions use our replication data with municipality-years present in both data-sets. Additionally, we remove observations from 2007 and 2010. Their population figures mostly come from a common IBGE source, but 2007 and 2010 estimates are taken from different sources. We remove those two years from the estimation sample. All estimates are in 2000BRL.
Our data - Common - Their FPM
This set of regressions use our replication data with municipality-years present in both data-sets. Additionally, to test whether our theoretical FPM values drive the differences in estimation by replacing our estimates with theirs. All estimates are in 2000BRL.
Our data - Common - Their LM
This set of regressions use our replication data with municipality-years present in both data-sets. Additionally, to test whether our Labor Market statistics drive the differences in estimation by replacing our estimates with theirs. All estimates are in 2000BRL.
Our data - Common - Their LM, FPM
This set of regressions use our replication data with municipality-years present in both data-sets. Additionally, to test whether our Labor Market and FPM statistics drive the differences in estimation by replacing our estimates with theirs. All estimates are in 2000BRL.
Our data - Common - Their LM, FPM, Cutoff-share
This set of regressions use our replication data with municipality-years present in both data-sets. Additionally, to test whether our Labor Market and FPM statistics drive the differences in estimation by replacing our estimates with theirs. All estimates are in 2000BRL. Moreover, we substitute our population-based sample restriction with theirs.
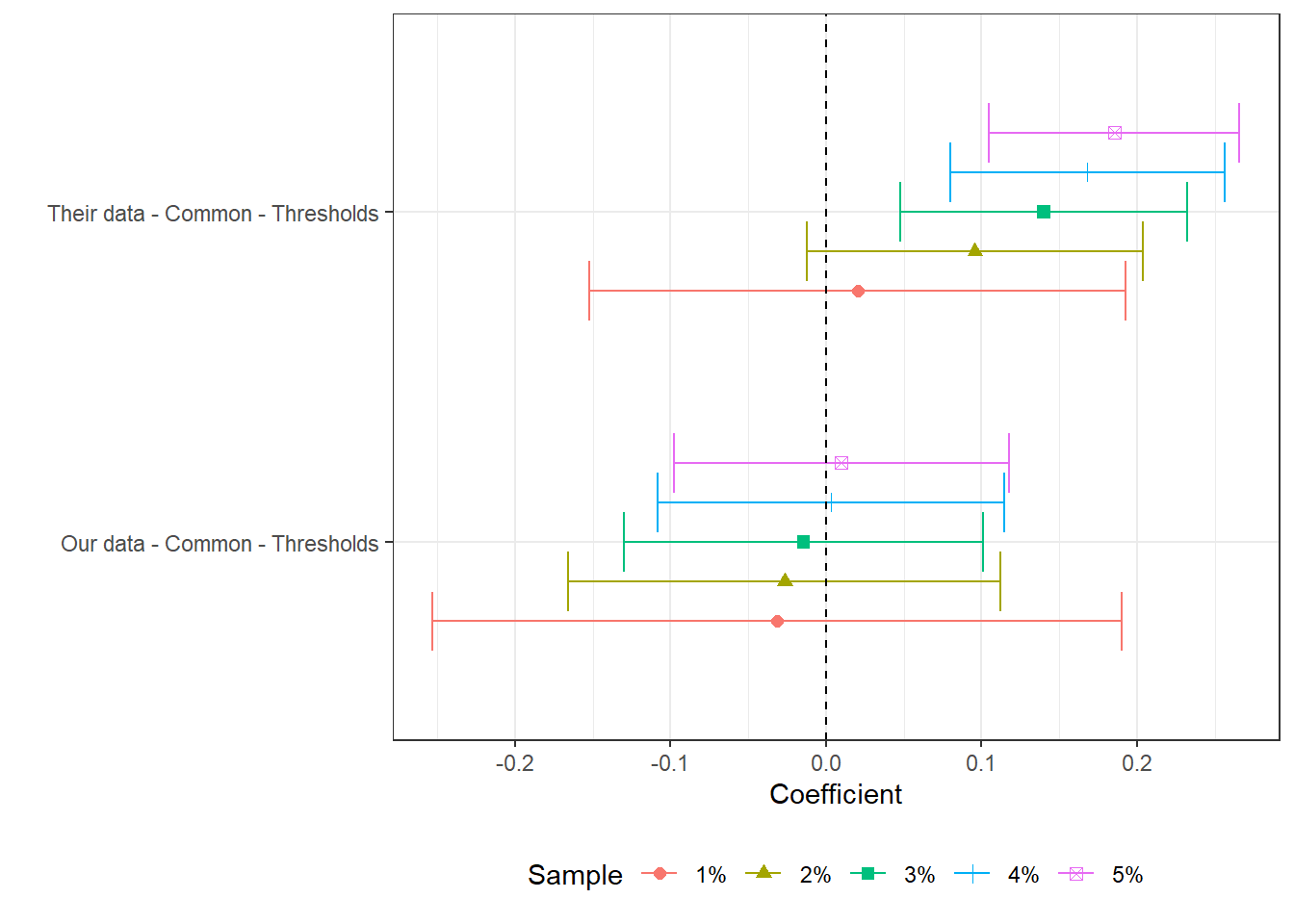
Our data - Common - Thresholds
This set of regressions use our replication data with municipality-years present in both data-sets. All estimates are in 2000BRL. In this set of regressions, we test what how differences in cut-off shares impact estimates and their significance.
Their data - 1997-2014 - 1998 BRL
This set of regressions use their original, unaltered data, with currency variables deflated according to the 1998 BRL.
Their data - 1997-2014 - Not Special Case
This set of regressions use their data for the full 1997-2014 sample. All estimates are in 2000BRL. We run the regressions excluding the special municipalities prior to 2008.
Their data - 1997-2014 - Not Special Case - 1997 Coeff
This set of regressions use their data for the full 1997-2014 sample. All estimates are in 2000BRL. We run the regressions on the entire sample excluding spacial cases prior to 2012 that are missing in their data. This tests the hypothesis that differences are generated by special cases.
Their data - Common
This set of regressions use their replication data with municipality-years present in both data-sets. All estimates are in 2000BRL.
Their data - Common - 1998 BRL
This set of regressions use their replication data with municipality-years present in both data-sets. All estimates are in 1998BRL.
Their data - Common - Remove 2007 & 2010
This set of regressions use their data with municipality-years present in both data-sets. Additionally, we remove observations from 2007 and 2010. Their population figures mostly come from a common IBGE source, but 2007 and 2010 estimates are taken from different sources. We remove those two years from the estimation sample.
Their data - Common - Thresholds
This set of regressions use their replication data with municipality-years present in both data-sets. All estimates are in 2000BRL. In this set of regressions, we test what how differences in cut-off shares impact estimates and their significance.
(a) The figure presents the point estimate and confidence interval of a labor market variable on log theoretical FPM, controlling for state-year, municipality and cutoff-year fixed effects. We cluster at the micro-region level. Estimates correspond to versions of table 7 in the original paper. Here, the labor market variable and corresponding cutoff share is specified in the caption. We present two estimates per regression, one for column (1) and another for column (3) in table 7. Practically, the difference is that the former does not control for first-order polynomials while the latter does. All estimations require some currency variable and are done in 2000BRL, unless otherwise specified. For consitency in the data presentation, we order regression names by the average number of stars its estimated coefficients have. Stars stand for levels of p-value, where *** stands for p<0.001, ** stands for p<0.05, * stands for p<0.1.
(a) The figure presents the point estimate and confidence interval of a labor market variable on log theoretical FPM, controlling for state-year, municipality and cutoff-year fixed effects. We cluster at the micro-region level. Estimates correspond to versions of table 7 in the original paper. Here, the labor market variable and corresponding cutoff share is specified in the caption. We present two estimates per regression, one for column (1) and another for column (3) in table 7. Practically, the difference is that the former does not control for first-order polynomials while the latter does. All estimations require some currency variable and are done in 2000BRL, unless otherwise specified. For consitency in the data presentation, we order regression names by the average number of stars its estimated coefficients have. Stars stand for levels of p-value, where *** stands for p<0.001, ** stands for p<0.05, * stands for p<0.1.
(a) The figure presents the point estimate and confidence interval of a labor market variable on log theoretical FPM, controlling for state-year, municipality and cutoff-year fixed effects. We cluster at the micro-region level. Estimates correspond to versions of table 7 in the original paper. Here, the labor market variable and corresponding cutoff share is specified in the caption. We present two estimates per regression, one for column (1) and another for column (3) in table 7. Practically, the difference is that the former does not control for first-order polynomials while the latter does. All estimations require some currency variable and are done in 2000BRL, unless otherwise specified. For consitency in the data presentation, we order regression names by the average number of stars its estimated coefficients have. Stars stand for levels of p-value, where *** stands for p<0.001, ** stands for p<0.05, * stands for p<0.1.
(a) The figure presents the point estimate and confidence interval of a labor market variable on log theoretical FPM, controlling for state-year, municipality and cutoff-year fixed effects. We cluster at the micro-region level. Estimates correspond to versions of table 7 in the original paper. Here, the labor market variable and corresponding cutoff share is specified in the caption. We present two estimates per regression, one for column (2) and another for column (4) in table 7. Practically, the difference is that the former does not control for first-order polynomials while the latter does. All estimations require some currency variable and are done in 2000BRL, unless otherwise specified. For consitency in the data presentation, we order regression names by the average number of stars its estimated coefficients have. Stars stand for levels of p-value, where *** stands for p<0.001, ** stands for p<0.05, * stands for p<0.1.
(a) The figure presents the point estimate and confidence interval of a labor market variable on log theoretical FPM, controlling for state-year, municipality and cutoff-year fixed effects. We cluster at the micro-region level. Estimates correspond to versions of table 7 in the original paper. Here, the labor market variable and corresponding cutoff share is specified in the caption. We present two estimates per regression, one for column (2) and another for column (4) in table 7. Practically, the difference is that the former does not control for first-order polynomials while the latter does. All estimations require some currency variable and are done in 2000BRL, unless otherwise specified. For consitency in the data presentation, we order regression names by the average number of stars its estimated coefficients have. Stars stand for levels of p-value, where *** stands for p<0.001, ** stands for p<0.05, * stands for p<0.1.
(a) The figure presents the point estimate and confidence interval of a labor market variable on log theoretical FPM, controlling for state-year, municipality and cutoff-year fixed effects. We cluster at the micro-region level. Estimates correspond to versions of table 7 in the original paper. Here, the labor market variable and corresponding cutoff share is specified in the caption. We present two estimates per regression, one for column (2) and another for column (4) in table 7. Practically, the difference is that the former does not control for first-order polynomials while the latter does. All estimations require some currency variable and are done in 2000BRL, unless otherwise specified. For consitency in the data presentation, we order regression names by the average number of stars its estimated coefficients have. Stars stand for levels of p-value, where *** stands for p<0.001, ** stands for p<0.05, * stands for p<0.1.
(a) The figure presents the point estimate and confidence interval of a labor market variable on log theoretical FPM, controlling for state-year, municipality and cutoff-year fixed effects. We cluster at the micro-region level. Estimates correspond to versions of table 7 in the original paper. Here, the labor market variable is specified in the caption. We present five estimates per regression. Each corresponds to the control specifications for columns (1) or (2) in table 7. Each regression estimate varies only because we change the neighborhood around the cut-off. All estimations require some currency variable and are done in 2000BRL, unless otherwise specified. For consitency in the data presentation, we order regression names by the average number of stars its estimated coefficients have. Stars stand for levels of p-value, where *** stands for p<0.001, ** stands for p<0.05, * stands for p<0.1.
(a) The figure presents the point estimate and confidence interval of a labor market variable on log theoretical FPM, controlling for state-year, municipality and cutoff-year fixed effects. We cluster at the micro-region level. Estimates correspond to versions of table 7 in the original paper. Here, the labor market variable is specified in the caption. We present five estimates per regression. Each corresponds to the control specifications for columns (1) or (2) in table 7. Each regression estimate varies only because we change the neighborhood around the cut-off. All estimations require some currency variable and are done in 2000BRL, unless otherwise specified. For consitency in the data presentation, we order regression names by the average number of stars its estimated coefficients have. Stars stand for levels of p-value, where *** stands for p<0.001, ** stands for p<0.05, * stands for p<0.1.
(a) The figure presents the point estimate and confidence interval of a labor market variable on log theoretical FPM, controlling for state-year, municipality and cutoff-year fixed effects. We cluster at the micro-region level. Estimates correspond to versions of table 7 in the original paper. Here, the labor market variable is specified in the caption. We present five estimates per regression. Each corresponds to the control specifications for columns (1) or (2) in table 7. Each regression estimate varies only because we change the neighborhood around the cut-off. All estimations require some currency variable and are done in 2000BRL, unless otherwise specified. For consitency in the data presentation, we order regression names by the average number of stars its estimated coefficients have. Stars stand for levels of p-value, where *** stands for p<0.001, ** stands for p<0.05, * stands for p<0.1.
Corbi, Raphael, Elias Papaioannou, and Paolo Surico. 2018. “Regional Transfer Multipliers.”The Review of Economic Studies 86 (5): 1901–34. https://doi.org/10.1093/restud/rdy069.